> ## Documentation Index
> Fetch the complete documentation index at: https://docs.brightdata.com/llms.txt
> Use this file to discover all available pages before exploring further.
# 使用 AI Agent 构建爬虫
> 使用 Bright Data Scraper Studio 的 AI Agent,通过一段自然语言提示词在大约 10 分钟内构建自定义网页爬虫,无需写代码。
Bright Data Scraper Studio 的 AI Agent 可以根据一段自然语言描述构建自定义网页爬虫。提供一个目标 URL 并描述您想要的数据;AI Agent 会生成输出 schema、编写爬虫代码,并交付一个可通过 API、手动或按计划触发的可运行爬虫。本教程将带您走完整个流程。
**预计用时:** 约 10 分钟
更喜欢使用终端?请使用 [Bright Data CLI](/cn/datasets/scraper-studio/build-with-the-cli) 在任意 shell 或编码助手(Claude Code、Cursor、Codex)的内嵌终端中构建相同的爬虫。
## 前提条件
* 一个 Bright Data 账户([免费注册](https://www.bright.cn/?hs_signup=1\&utm_source=docs))
* 您想抓取的网站 URL
## 使用 AI Agent 构建您的第一个爬虫
在 Bright Data 控制面板的左侧菜单中点击 **Scrapers**,然后打开 **Scraper Studio**。
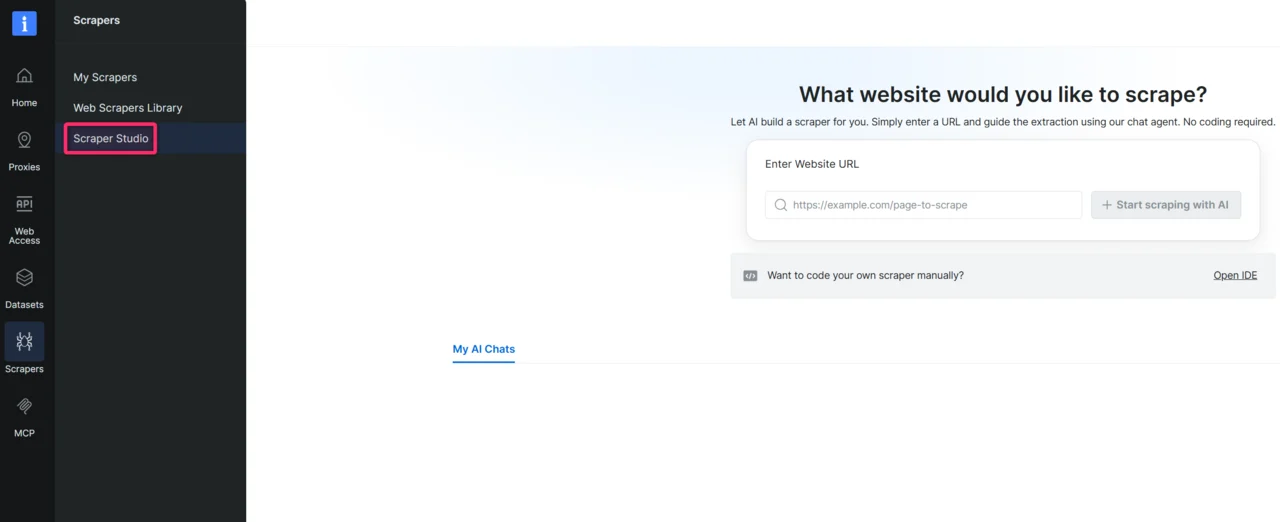 将您想要抓取的页面 URL 粘贴到聊天输入框。除了 URL,请补充能帮助 AI 一次性构建更准确爬虫的上下文。您提供的上下文越多,生成代码的质量就越高。
将您想要抓取的页面 URL 粘贴到聊天输入框。除了 URL,请补充能帮助 AI 一次性构建更准确爬虫的上下文。您提供的上下文越多,生成代码的质量就越高。
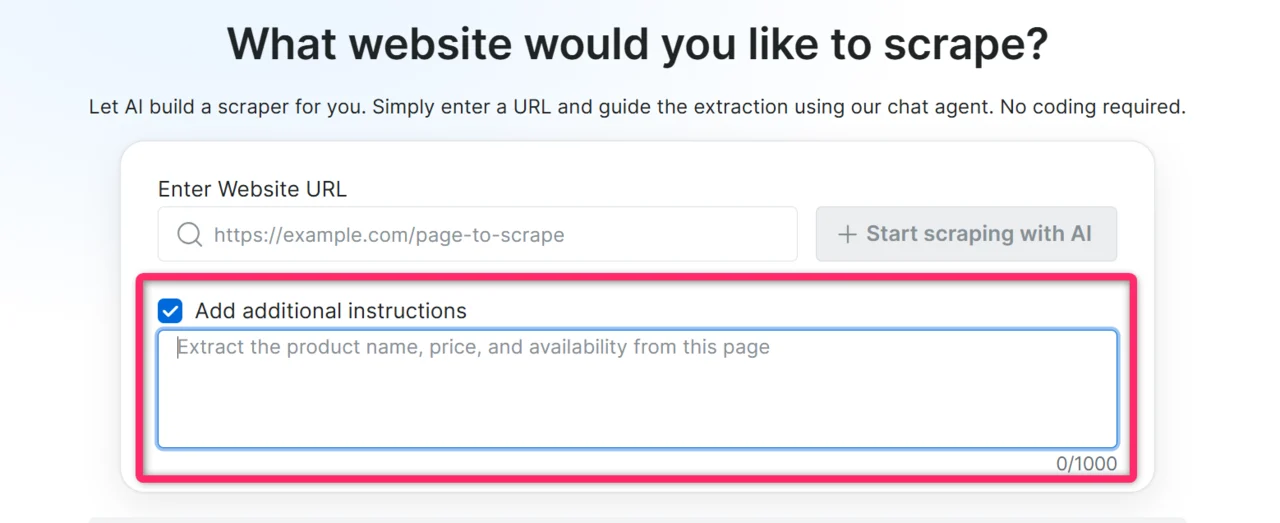 可补充的上下文:
* **您需要的具体字段**:"我需要价格、标题和库存状态"
* **数据在页面上的位置**:"价格在产品详情面板中,而不是列表页"
* **访问数据所需的操作**:"点击'Show more' 加载完整描述"
* **CSS 选择器**(如果您知道):`.product-price span.amount`
* **页面加载行为**(站点缓慢或懒加载内容时):"结果动态加载,请给它更多时间"
> **预期结果:** AI Agent 确认 URL,可能会针对您想要的数据提出一两个澄清问题。
用自然语言回复。
> **预期结果:** AI Agent 生成一份 schema —— 一组包含字段名与数据类型的结构化列表,它将成为爬虫的输出结构。
通读生成的 schema。您有四种选择:
* **批准**:点击 Approve 按当前 schema 接受
* **拒绝**:在聊天中输入反馈(例如"删除 image 字段并新增 rating 字段"),AI 会重新生成 schema
* **就地编辑**:无需返回聊天,直接修改 schema
* **上传自己的 schema**:使用您自己的 schema 文件;可下载示例文件以了解正确格式
就地编辑选项:
* **编辑字段**(铅笔图标):修改字段名或数据类型
* **删除字段**(垃圾桶图标):移除您不需要的字段
* **添加字段**(加号按钮):向 schema 增加新字段
可补充的上下文:
* **您需要的具体字段**:"我需要价格、标题和库存状态"
* **数据在页面上的位置**:"价格在产品详情面板中,而不是列表页"
* **访问数据所需的操作**:"点击'Show more' 加载完整描述"
* **CSS 选择器**(如果您知道):`.product-price span.amount`
* **页面加载行为**(站点缓慢或懒加载内容时):"结果动态加载,请给它更多时间"
> **预期结果:** AI Agent 确认 URL,可能会针对您想要的数据提出一两个澄清问题。
用自然语言回复。
> **预期结果:** AI Agent 生成一份 schema —— 一组包含字段名与数据类型的结构化列表,它将成为爬虫的输出结构。
通读生成的 schema。您有四种选择:
* **批准**:点击 Approve 按当前 schema 接受
* **拒绝**:在聊天中输入反馈(例如"删除 image 字段并新增 rating 字段"),AI 会重新生成 schema
* **就地编辑**:无需返回聊天,直接修改 schema
* **上传自己的 schema**:使用您自己的 schema 文件;可下载示例文件以了解正确格式
就地编辑选项:
* **编辑字段**(铅笔图标):修改字段名或数据类型
* **删除字段**(垃圾桶图标):移除您不需要的字段
* **添加字段**(加号按钮):向 schema 增加新字段
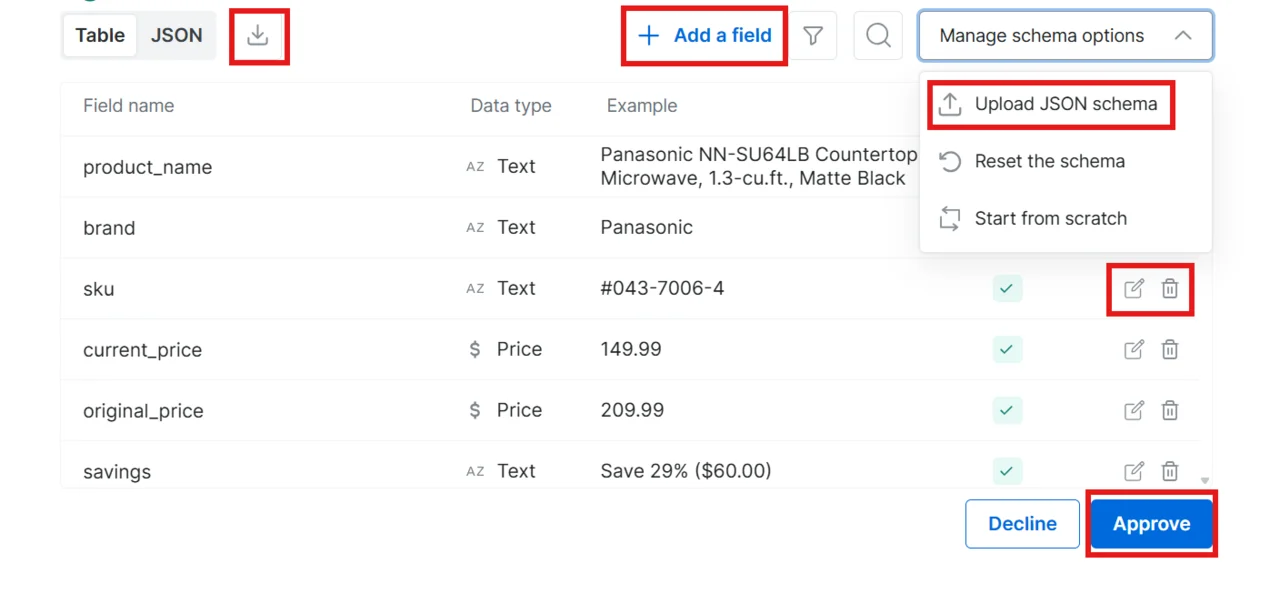 其他控件:
* **Start from scratch(从头开始)**:清除所有字段,您可以从空白状态手动构建 schema
* **Reset the schema(重置 schema)**:放弃就地修改,恢复到原始的 AI 生成版本
准备好后点击 **Approve**。
> **预期结果:** 批准后,AI Agent 开始生成爬虫代码。
AI 会编写完整的爬虫,包括提取逻辑、导航处理、数据校验和错误处理。这需要几分钟。
> **预期结果:** 出现确认弹窗,提示您的爬虫已准备就绪。
其他控件:
* **Start from scratch(从头开始)**:清除所有字段,您可以从空白状态手动构建 schema
* **Reset the schema(重置 schema)**:放弃就地修改,恢复到原始的 AI 生成版本
准备好后点击 **Approve**。
> **预期结果:** 批准后,AI Agent 开始生成爬虫代码。
AI 会编写完整的爬虫,包括提取逻辑、导航处理、数据校验和错误处理。这需要几分钟。
> **预期结果:** 出现确认弹窗,提示您的爬虫已准备就绪。
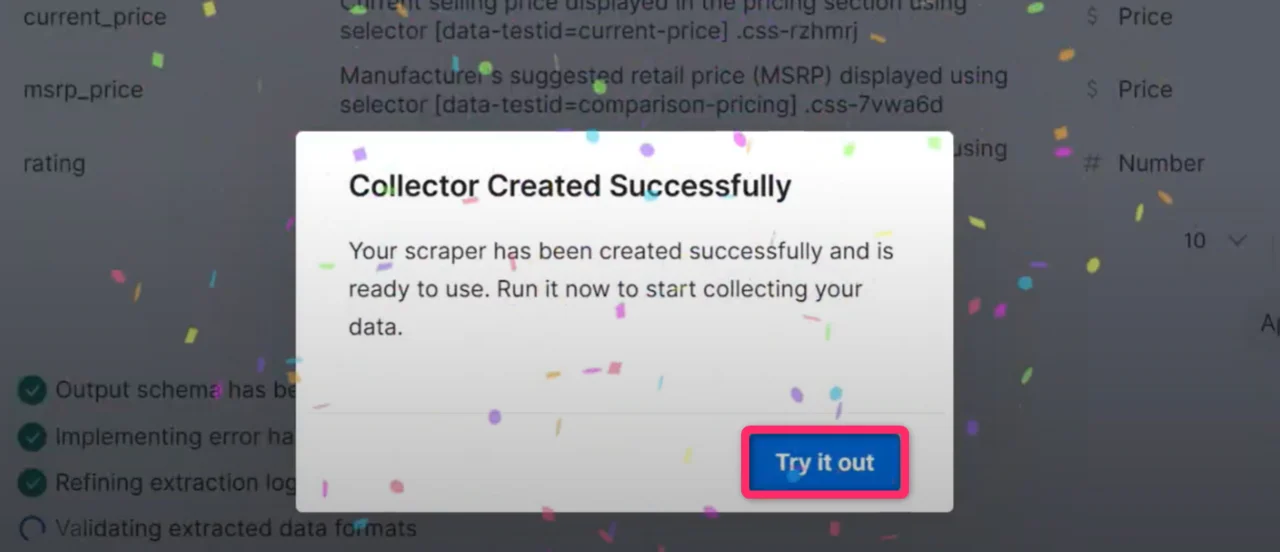 点击 **Try it out**(试一试)打开 Initiate Manually(手动启动)页面。检查采集设置并点击 **Start** 开始数据采集。
点击 **Try it out**(试一试)打开 Initiate Manually(手动启动)页面。检查采集设置并点击 **Start** 开始数据采集。
 您也可以选择其他启动方式:
* **[通过 API 启动](/cn/api-reference/scraper-studio-api/ai-flow/overview):** 无需打开控制面板即可以编程方式触发爬虫
* **按计划运行:** 按每日、每周或自定义间隔运行爬虫
> **预期结果:** 爬虫开始采集数据。可从 Runs 仪表盘监控进度,任务完成后以 JSON、NDJSON、CSV 或 XLSX 格式下载结果。
爬虫准备好后,可以使用[自我修复工具](/cn/datasets/scraper-studio/self-healing-tool)进行自然语言修改,也可以在 Bright Data Scraper Studio IDE 中打开代码直接编辑。
## AI Agent 能构建哪些爬虫?
当您需要的数据在[数据集市场](/cn/datasets/marketplace)中尚未提供时,使用 Bright Data Scraper Studio AI Agent。对于 Bright Data 已经覆盖的站点(亚马逊、沃尔玛、LinkedIn、eBay 等),市场内的预构建爬虫比自行构建更快、更经济。AI Agent 适用于区域性电商、B2B 产品目录、垂直细分领域,以及任何没有预构建爬虫的站点。
AI Agent 可以构建以下五种爬虫类型之一。请选择与您拥有的输入和所需输出相匹配的类型。
| 爬虫类型 | 您提供的输入 | 您获得的输出 | 每个输入访问的页面数 |
| ------------------- | --------------------- | ------------------------------ | ---------- |
| **PDP** | 产品 URL 列表 | 完整的逐产品详情 | 1 |
| **Discovery** | 分类页 / 列表页 URL | 列表级数据行(标题、价格、排名) | 1 |
| **Discovery + PDP** | 分类页 / 列表页 URL | 该分类下每个商品的完整产品详情 | 1 + N |
| **搜索** | 关键词(可选附加国家/地区) | Discovery 或 Discovery + PDP 形态 | 1 + M |
| **Sitemap** | 域名或 `sitemap.xml` URL | sitemap 中每个 URL 的完整逐页详情 | 1 + N |
**不是网页爬取器。** 不要传入主页并要求"抓取所有内容"。每个爬虫只针对一种数据形态。
### 何时使用 PDP 爬虫?
当您拥有一组具体的产品 URL 并需要完整的逐产品详情时,使用 PDP 爬虫。每个输入 URL 产生一行数据。
**示例:** 来自区域性零售商(如 [dm.de](https://www.dm.de))的 100 个产品 URL → 100 行数据,包含标题、价格、库存状态、图片以及您在 schema 中定义的其他字段。
将以下内容粘贴到 AI Agent 对话框:
```text Prompt theme={null}
为 dm.de 构建一个 PDP 爬虫。对于我提供的每个产品 URL,提取产品标题、价格、库存状态、品牌、评分和所有产品图片 URL。每个输入 URL 返回一行数据。
```
### 何时使用 Discovery 爬虫?
当您需要单个列表页的项目概览,且无需逐产品详情时,使用 Discovery 爬虫。每个输入 URL 产生 N 行数据,其中 N 等于列表中的项目数。
**示例:** 像 `https://www.dm.de/baby-und-kind` 这样的分类页 → 30 行数据,包含标题、价格、评分和列表位置。不包含描述,不包含完整图集。
将以下内容粘贴到 AI Agent 对话框:
```text Prompt theme={null}
为 dm.de 分类页 https://www.dm.de/baby-und-kind 构建一个 Discovery 爬虫。为列表中显示的每个项目返回一行数据,包含标题、价格、评分和列表位置。不要打开单个产品页面。
```
### 何时使用 Discovery + PDP 爬虫?
当您需要整个分类的完整逐产品详情时,使用 Discovery + PDP 爬虫。每个输入 URL 产生 N 行数据,每行都是完整的 PDP 形态。
这是成本最高的类型。一个包含 200 个产品的分类 URL,其成本约为单次 PDP 抓取的 200 倍。
**示例:** 区域性零售商的分类页(如 [decathlon.fr](https://www.decathlon.fr)) → 该分类中每个商品的完整产品详情。
将以下内容粘贴到 AI Agent 对话框:
```text Prompt theme={null}
为 decathlon.fr 上的某个分类页(例如跑鞋之类的运动分类)构建一个 Discovery + PDP 爬虫。找出该分类中的每个产品,打开每个产品页面,并提取完整详情:标题、价格、库存状态、描述、评分和图片 URL。每个产品返回一行数据。
```
### 何时使用搜索爬虫?
当您没有具体 URL 时,使用搜索爬虫。提供一个关键词,并可选附加国家/地区;AI Agent 会根据您要求的是列表级字段还是完整 PDP 详情,选择 Discovery 或 Discovery + PDP 形态。
**示例:** 在 B2B 配件站点(如 [autodoc.de](https://www.autodoc.de))搜索关键词"brake pads" → 以列表级或完整 PDP 形态返回匹配的产品结果。
将以下内容粘贴到 AI Agent 对话框:
```text Prompt theme={null}
为 autodoc.de 构建一个搜索爬虫。针对关键词 "brake pads"(国家/地区:德国),返回匹配的产品,包含标题、价格、品牌和产品 URL。无需打开每个产品页面。
```
### 何时使用 Sitemap 爬虫?
当您需要采集网站上大量页面的数据,且该网站通过 XML sitemap 公开这些页面 URL 时,使用 Sitemap 爬虫。Sitemap 让爬虫直接发现 URL,无需逐层点击分类页、翻页或搜索结果,因此适用于大型电商网站、市场平台、商品目录、博客和文档网站等。
提供一个域名或一个 sitemap URL。每个 sitemap 会产生 N 个发现的页面 URL,爬虫随后访问每个相关页面,采集您在 schema 中定义的字段。
**示例:** 像 [dm.de](https://www.dm.de) 这样的域名,或其 sitemap `https://www.dm.de/sitemap.xml` → 从 sitemap 中发现所有产品 URL → 访问每个产品页面 → 采集完整产品详情。
将以下内容粘贴到 AI Agent 对话框:
```text Prompt theme={null}
为 dm.de 构建一个 Sitemap 爬虫。从 sitemap 中采集所有产品 URL,访问每个产品页面,并提取产品名称、价格、SKU、描述、图片 URL 和库存状态。每个产品返回一行数据。
```
如果您已经有 sitemap URL,可让 AI Agent 直接使用它:
```text Prompt theme={null}
使用此 sitemap 构建一个爬虫:https://www.dm.de/sitemap.xml。提取所有产品页面 URL,访问每个产品页面,并采集所需的产品详情字段。
```
## 常见问题
可以。AI Agent 生成的每个爬虫都可以在 Bright Data Scraper Studio IDE 中打开并直接编辑。如果您不想写代码,可以使用[自我修复工具](/cn/datasets/scraper-studio/self-healing-tool)用自然语言提出修改请求。
AI Agent 生成的爬虫运行在 Bright Data 的代理与解封基础设施上,可处理大多数反机器人防护。对于需要登录会话的站点,请在 IDE 中构建爬虫,并使用 `set_session_cookie()` 或与目标站点匹配的认证方式。
AI Agent 依赖您提供的上下文。如果输出不符合预期,请拒绝 schema 并补充更多细节:字段名、选择器或数据所在的确切页面区域。您也可以在事后使用[自我修复工具](/cn/datasets/scraper-studio/self-healing-tool)对已生成的爬虫进行细化。
## 相关内容
在终端或任意编码助手中构建相同的爬虫
通过直接编写 JavaScript 构建爬虫
使用自然语言提示词更新已生成的爬虫
您也可以选择其他启动方式:
* **[通过 API 启动](/cn/api-reference/scraper-studio-api/ai-flow/overview):** 无需打开控制面板即可以编程方式触发爬虫
* **按计划运行:** 按每日、每周或自定义间隔运行爬虫
> **预期结果:** 爬虫开始采集数据。可从 Runs 仪表盘监控进度,任务完成后以 JSON、NDJSON、CSV 或 XLSX 格式下载结果。
爬虫准备好后,可以使用[自我修复工具](/cn/datasets/scraper-studio/self-healing-tool)进行自然语言修改,也可以在 Bright Data Scraper Studio IDE 中打开代码直接编辑。
## AI Agent 能构建哪些爬虫?
当您需要的数据在[数据集市场](/cn/datasets/marketplace)中尚未提供时,使用 Bright Data Scraper Studio AI Agent。对于 Bright Data 已经覆盖的站点(亚马逊、沃尔玛、LinkedIn、eBay 等),市场内的预构建爬虫比自行构建更快、更经济。AI Agent 适用于区域性电商、B2B 产品目录、垂直细分领域,以及任何没有预构建爬虫的站点。
AI Agent 可以构建以下五种爬虫类型之一。请选择与您拥有的输入和所需输出相匹配的类型。
| 爬虫类型 | 您提供的输入 | 您获得的输出 | 每个输入访问的页面数 |
| ------------------- | --------------------- | ------------------------------ | ---------- |
| **PDP** | 产品 URL 列表 | 完整的逐产品详情 | 1 |
| **Discovery** | 分类页 / 列表页 URL | 列表级数据行(标题、价格、排名) | 1 |
| **Discovery + PDP** | 分类页 / 列表页 URL | 该分类下每个商品的完整产品详情 | 1 + N |
| **搜索** | 关键词(可选附加国家/地区) | Discovery 或 Discovery + PDP 形态 | 1 + M |
| **Sitemap** | 域名或 `sitemap.xml` URL | sitemap 中每个 URL 的完整逐页详情 | 1 + N |
**不是网页爬取器。** 不要传入主页并要求"抓取所有内容"。每个爬虫只针对一种数据形态。
### 何时使用 PDP 爬虫?
当您拥有一组具体的产品 URL 并需要完整的逐产品详情时,使用 PDP 爬虫。每个输入 URL 产生一行数据。
**示例:** 来自区域性零售商(如 [dm.de](https://www.dm.de))的 100 个产品 URL → 100 行数据,包含标题、价格、库存状态、图片以及您在 schema 中定义的其他字段。
将以下内容粘贴到 AI Agent 对话框:
```text Prompt theme={null}
为 dm.de 构建一个 PDP 爬虫。对于我提供的每个产品 URL,提取产品标题、价格、库存状态、品牌、评分和所有产品图片 URL。每个输入 URL 返回一行数据。
```
### 何时使用 Discovery 爬虫?
当您需要单个列表页的项目概览,且无需逐产品详情时,使用 Discovery 爬虫。每个输入 URL 产生 N 行数据,其中 N 等于列表中的项目数。
**示例:** 像 `https://www.dm.de/baby-und-kind` 这样的分类页 → 30 行数据,包含标题、价格、评分和列表位置。不包含描述,不包含完整图集。
将以下内容粘贴到 AI Agent 对话框:
```text Prompt theme={null}
为 dm.de 分类页 https://www.dm.de/baby-und-kind 构建一个 Discovery 爬虫。为列表中显示的每个项目返回一行数据,包含标题、价格、评分和列表位置。不要打开单个产品页面。
```
### 何时使用 Discovery + PDP 爬虫?
当您需要整个分类的完整逐产品详情时,使用 Discovery + PDP 爬虫。每个输入 URL 产生 N 行数据,每行都是完整的 PDP 形态。
这是成本最高的类型。一个包含 200 个产品的分类 URL,其成本约为单次 PDP 抓取的 200 倍。
**示例:** 区域性零售商的分类页(如 [decathlon.fr](https://www.decathlon.fr)) → 该分类中每个商品的完整产品详情。
将以下内容粘贴到 AI Agent 对话框:
```text Prompt theme={null}
为 decathlon.fr 上的某个分类页(例如跑鞋之类的运动分类)构建一个 Discovery + PDP 爬虫。找出该分类中的每个产品,打开每个产品页面,并提取完整详情:标题、价格、库存状态、描述、评分和图片 URL。每个产品返回一行数据。
```
### 何时使用搜索爬虫?
当您没有具体 URL 时,使用搜索爬虫。提供一个关键词,并可选附加国家/地区;AI Agent 会根据您要求的是列表级字段还是完整 PDP 详情,选择 Discovery 或 Discovery + PDP 形态。
**示例:** 在 B2B 配件站点(如 [autodoc.de](https://www.autodoc.de))搜索关键词"brake pads" → 以列表级或完整 PDP 形态返回匹配的产品结果。
将以下内容粘贴到 AI Agent 对话框:
```text Prompt theme={null}
为 autodoc.de 构建一个搜索爬虫。针对关键词 "brake pads"(国家/地区:德国),返回匹配的产品,包含标题、价格、品牌和产品 URL。无需打开每个产品页面。
```
### 何时使用 Sitemap 爬虫?
当您需要采集网站上大量页面的数据,且该网站通过 XML sitemap 公开这些页面 URL 时,使用 Sitemap 爬虫。Sitemap 让爬虫直接发现 URL,无需逐层点击分类页、翻页或搜索结果,因此适用于大型电商网站、市场平台、商品目录、博客和文档网站等。
提供一个域名或一个 sitemap URL。每个 sitemap 会产生 N 个发现的页面 URL,爬虫随后访问每个相关页面,采集您在 schema 中定义的字段。
**示例:** 像 [dm.de](https://www.dm.de) 这样的域名,或其 sitemap `https://www.dm.de/sitemap.xml` → 从 sitemap 中发现所有产品 URL → 访问每个产品页面 → 采集完整产品详情。
将以下内容粘贴到 AI Agent 对话框:
```text Prompt theme={null}
为 dm.de 构建一个 Sitemap 爬虫。从 sitemap 中采集所有产品 URL,访问每个产品页面,并提取产品名称、价格、SKU、描述、图片 URL 和库存状态。每个产品返回一行数据。
```
如果您已经有 sitemap URL,可让 AI Agent 直接使用它:
```text Prompt theme={null}
使用此 sitemap 构建一个爬虫:https://www.dm.de/sitemap.xml。提取所有产品页面 URL,访问每个产品页面,并采集所需的产品详情字段。
```
## 常见问题
可以。AI Agent 生成的每个爬虫都可以在 Bright Data Scraper Studio IDE 中打开并直接编辑。如果您不想写代码,可以使用[自我修复工具](/cn/datasets/scraper-studio/self-healing-tool)用自然语言提出修改请求。
AI Agent 生成的爬虫运行在 Bright Data 的代理与解封基础设施上,可处理大多数反机器人防护。对于需要登录会话的站点,请在 IDE 中构建爬虫,并使用 `set_session_cookie()` 或与目标站点匹配的认证方式。
AI Agent 依赖您提供的上下文。如果输出不符合预期,请拒绝 schema 并补充更多细节:字段名、选择器或数据所在的确切页面区域。您也可以在事后使用[自我修复工具](/cn/datasets/scraper-studio/self-healing-tool)对已生成的爬虫进行细化。
## 相关内容
在终端或任意编码助手中构建相同的爬虫
通过直接编写 JavaScript 构建爬虫
使用自然语言提示词更新已生成的爬虫