> ## Documentation Index
> Fetch the complete documentation index at: https://docs.brightdata.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Scraper Studio 中的 WARC 快照
> 在 Bright Data Scraper Studio 中启用 WARC 文件输出,归档 Browser worker 爬取期间捕获的完整 HTTP 响应,用于合规与研究场景。
Bright Data Scraper Studio 可以在抓取每个页面的同时返回一个 WARC(Web ARChive)文件,记录浏览器在采集过程中收到的完整 HTTP 响应。该文件可用于数字保存、审计追踪、研究可复现性,以及任何需要站点返回内容字节级证据的工作流。
## 什么是 WARC 文件?
WARC 是一种用于存储网页抓取与 HTTP 交互的 ISO 标准文件格式(ISO 28500)。一个 WARC 文件会保存页面加载过程中浏览器侧每一次抓取的原始请求与响应对、首部、时间戳和负载字节,涵盖 HTML、CSS、JavaScript、图片以及 XHR 请求。
WARC 快照仅适用于 Browser worker 爬虫。Code worker 爬虫不运行浏览器,因此没有可归档的浏览器层网络流量。
## 如何为爬虫启用 WARC 输出?
前往 [www.bright.cn/cp](https://www.bright.cn/cp/scrapers),选择您想归档的爬虫,点击 **Edit code**(编辑代码)在 IDE 中打开它。
在 **Output Schema**(输出 schema)面板中找到 `additional_data` 段,点击 `warc_snapshot` 旁的眼睛图标将其打开。
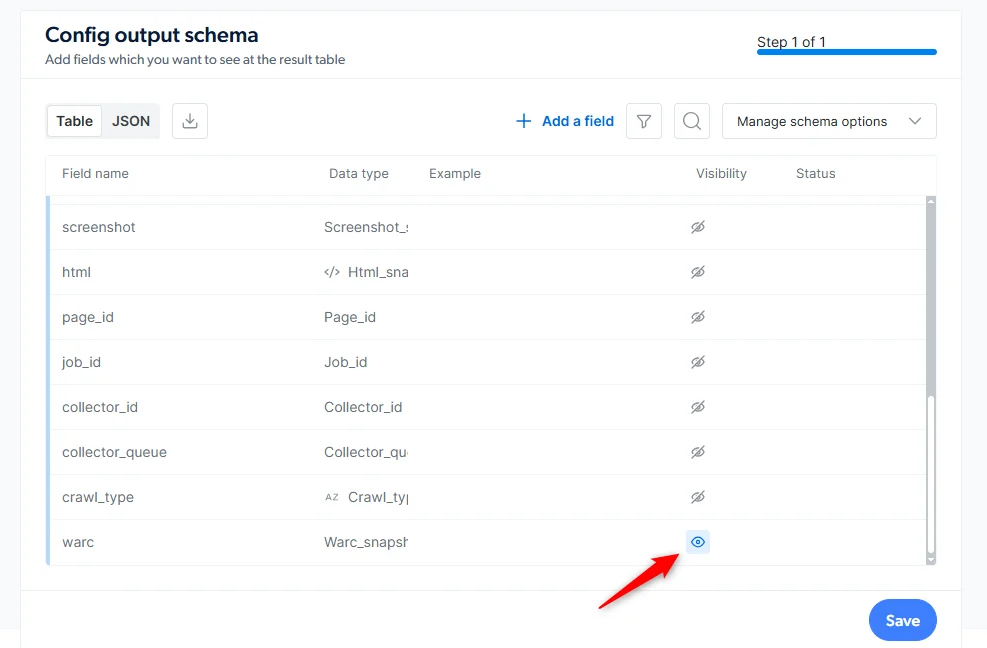 将爬虫保存到生产环境并触发一次运行。爬虫采集的每个页面都会生成一份对应的 WARC 文件。
Bright Data 会按您为爬虫配置的交付方式投递 WARC 文件:API 下载、webhook、S3、Google Cloud Storage、Azure、SFTP 或电子邮件。
交付选项参见[启动数据收集与交付](/cn/datasets/scraper-studio/initiate-collection-and-delivery-options)。
## 如何最大化 WARC 的捕获内容?
WARC 捕获会记录浏览器在页面加载期间发出的每一次请求,但仅限于浏览器仍在主动加载页面的时段。为捕获更多内容,请在爬虫继续推进前给浏览器留出足够的加载时间:
* 在交互代码末尾调用 `wait_network_idle()`,让浏览器在 Bright Data Scraper Studio 最终生成 WARC 文件之前完成所有进行中的 XHR 和 fetch 请求
* 优先使用 Browser worker 而非 Code worker。只有 Browser worker 的网络流量会被记录;Code worker 中的原始 `request()` 调用不会被记录
* 如果页面通过滚动懒加载媒体,请在 `wait_network_idle()` 之前调用 `scroll_to('bottom')` 或 `load_more()`,让浏览器真正去抓取这些资源
## 常见问题
页面加载期间捕获的每一个浏览器侧请求与响应:HTML 文档、CSS、JavaScript、图片、字体、XHR 和 fetch 调用。每条记录都包含请求行、首部和浏览器接收到的响应负载。
不适用。WARC 快照需要 Browser worker,因为捕获发生在浏览器网络层。Code worker 爬虫直接发送原始 HTTP 请求,没有浏览器可供记录流量。
WARC 文件通过爬虫已配置的交付方式投递(API 下载、webhook、云存储、SFTP 或电子邮件)。文件下载按 GB 计费,与 CPM 页面加载费用分开。当前费率参见 [Scraper Studio 规格说明](/cn/datasets/scraper-studio/specifications)。
WARC 快照遵循爬虫的快照保留策略:批量采集保留 16 天,实时采集保留 7 天。请在保留窗口关闭前导出或下载文件。Bright Data 不会恢复已过期的数据。
## 相关内容
计费模式、保留期限与基础设施限制
设置 WARC 文件与采集数据的交付目标
将爬虫保存到生产环境并触发一次运行。爬虫采集的每个页面都会生成一份对应的 WARC 文件。
Bright Data 会按您为爬虫配置的交付方式投递 WARC 文件:API 下载、webhook、S3、Google Cloud Storage、Azure、SFTP 或电子邮件。
交付选项参见[启动数据收集与交付](/cn/datasets/scraper-studio/initiate-collection-and-delivery-options)。
## 如何最大化 WARC 的捕获内容?
WARC 捕获会记录浏览器在页面加载期间发出的每一次请求,但仅限于浏览器仍在主动加载页面的时段。为捕获更多内容,请在爬虫继续推进前给浏览器留出足够的加载时间:
* 在交互代码末尾调用 `wait_network_idle()`,让浏览器在 Bright Data Scraper Studio 最终生成 WARC 文件之前完成所有进行中的 XHR 和 fetch 请求
* 优先使用 Browser worker 而非 Code worker。只有 Browser worker 的网络流量会被记录;Code worker 中的原始 `request()` 调用不会被记录
* 如果页面通过滚动懒加载媒体,请在 `wait_network_idle()` 之前调用 `scroll_to('bottom')` 或 `load_more()`,让浏览器真正去抓取这些资源
## 常见问题
页面加载期间捕获的每一个浏览器侧请求与响应:HTML 文档、CSS、JavaScript、图片、字体、XHR 和 fetch 调用。每条记录都包含请求行、首部和浏览器接收到的响应负载。
不适用。WARC 快照需要 Browser worker,因为捕获发生在浏览器网络层。Code worker 爬虫直接发送原始 HTTP 请求,没有浏览器可供记录流量。
WARC 文件通过爬虫已配置的交付方式投递(API 下载、webhook、云存储、SFTP 或电子邮件)。文件下载按 GB 计费,与 CPM 页面加载费用分开。当前费率参见 [Scraper Studio 规格说明](/cn/datasets/scraper-studio/specifications)。
WARC 快照遵循爬虫的快照保留策略:批量采集保留 16 天,实时采集保留 7 天。请在保留窗口关闭前导出或下载文件。Bright Data 不会恢复已过期的数据。
## 相关内容
计费模式、保留期限与基础设施限制
设置 WARC 文件与采集数据的交付目标