我可以选择 Browser API 抓取的国家吗?
我可以选择 Browser API 抓取的国家吗?
Browser API 会自动为每个请求选择最佳的 IP 类型和位置,利用 Bright Data 的高级解锁功能。虽然可以指定位置,但通常不建议这样做,因为自动化系统能确保页面访问的最佳成功率。如果您需要从特定国家启动,可以在端点中的用户名后添加
-country 标志以及相应的两位 ISO 代码。完整说明和示例请参阅我们的位置定位文档。如果需要定位到特定区域(不仅仅是国家),请查看我们的Proxy.setLocation 指南。Browser API 完全支持哪些编程语言和工具?
Browser API 完全支持哪些编程语言和工具?
- Browser API 对以下组合提供完整原生支持:
- Node.js: Puppeteer (原生), Playwright (原生), Selenium WebDriverJS
- Python: Playwright for Python, Selenium WebDriver for Python
- Java: Playwright for Java, Selenium WebDriver for Java
- C# (.NET): Playwright for .NET, Selenium WebDriver for .NET
如何在其他语言和工具中使用 Browser API?
如何在其他语言和工具中使用 Browser API?
- Browser API 也可以通过社区或第三方库集成到其他语言:
- Java: Puppeteer Java
- Ruby: Puppeteer-Ruby, playwright-ruby-client, Selenium WebDriver for Ruby
- Go: chromedp, playwright-go, Selenium WebDriver for Go
- 对于未列出的语言,如果库支持远程 Chrome DevTools Protocol 或 WebDriver,也可以进行集成。
为了获得最佳效果并访问完整功能集,请使用完全支持语言常见问题中列出的原生集成。
我如何查看验证码的状态?
我如何查看验证码的状态?
在 Browser API 会话中,我如何调试后台发生的事情?
在 Browser API 会话中,我如何调试后台发生的事情?
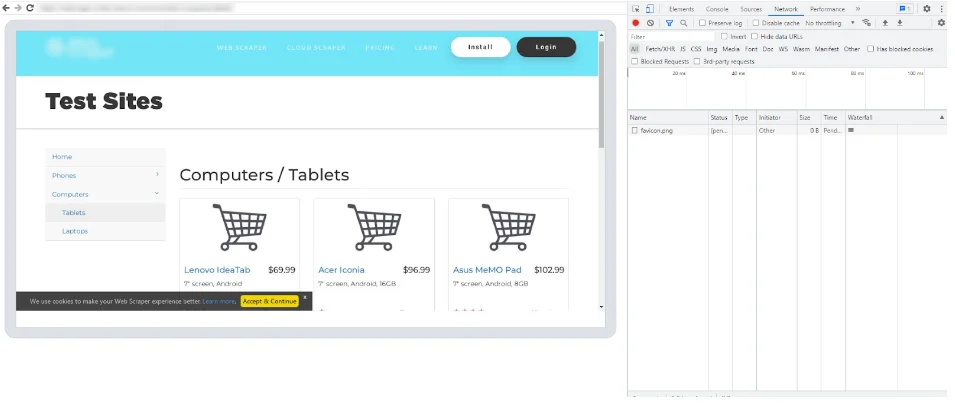
您可以通过在本地启动 Browser API Debugger 来监控实时 Browser API 会话。这类似于在 Puppeteer 中将 headless 浏览器设置为 ‘FALSE’。Browser API Debugger 是一个有价值的资源,可让您与 Chrome Dev Tools 一起检查、分析和微调代码,从而实现更好的控制、可视性和效率。
我在哪里可以找到 Browser API Debugger?
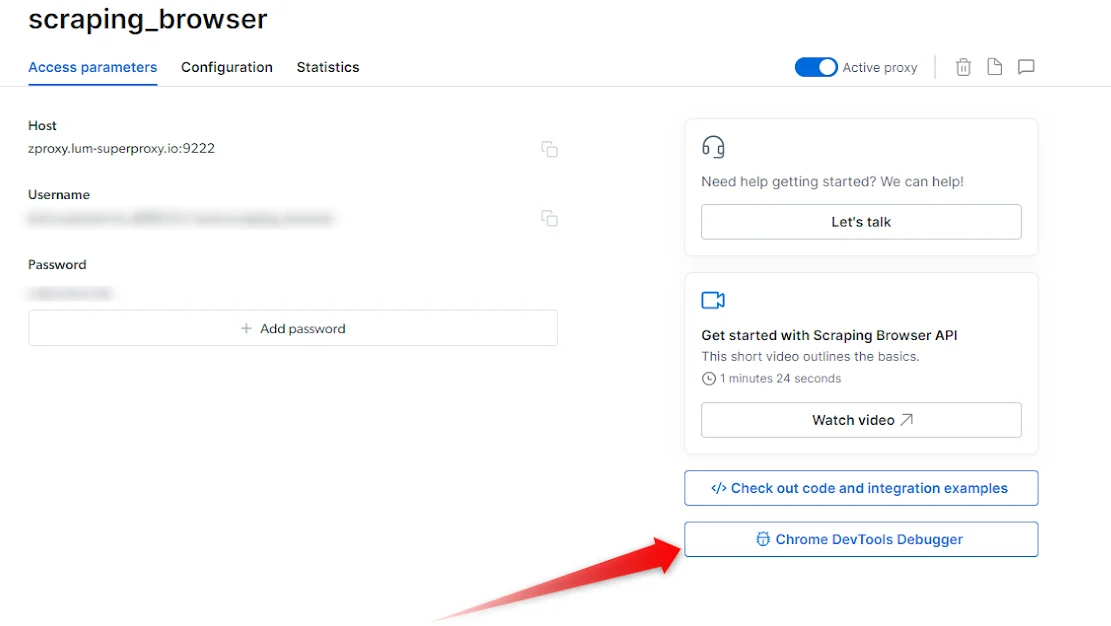
Browser API Debugger 可通过两种方式启动:- 通过控制面板手动启动
-
通过脚本远程启动
利用 Chrome Dev Tools
- 通过控制面板
- 通过代码(远程)
- 连接实时会话后,您可以使用 Chrome Dev Tools 的强大功能。
- 使用 Dev Tools 界面检查 HTML 元素、分析网络请求、调试 JavaScript 代码并监控性能。利用断点、控制台日志和其他调试技术识别和解决代码中的问题。
如何自动在本地启动 DevTools 以查看实时浏览器会话?
如何自动在本地启动 DevTools 以查看实时浏览器会话?
如果希望在每个会话中自动启动 DevTools 以查看实时浏览器会话,可以集成以下代码片段:
NodeJS - Puppeteer
如何获取浏览器操作的截图?
如何获取浏览器操作的截图?
- 触发截图
- 本地启动 DevTools
为什么某些页面的初次导航比其他页面更慢?
为什么某些页面的初次导航比其他页面更慢?
最常见的错误代码有哪些?
最常见的错误代码有哪些?
| 错误代码 | 含义 | 应对方法 |
| Unexpected server response: 407 | 远程浏览器端口问题 | 请检查远程浏览器端口。Browser API 的正确端口为 9222。 |
| Unexpected server response: 403 | 认证错误 | 检查认证凭据(用户名、密码),并确保使用 Bright Data 控制面板中的正确 “Browser API” 区域。 |
| Unexpected server response: 503 | 服务不可用 | 我们可能正在扩展浏览器以满足需求,请 1 分钟后重试。 |
无法与 Browser API 建立连接,是连接问题吗?
无法与 Browser API 建立连接,是连接问题吗?
如何将 Browser API 集成到 .NET Puppeteer Sharp?
如何将 Browser API 集成到 .NET Puppeteer Sharp?
使用 C# 集成 Browser API 需要修补 PuppeteerSharp 库以支持 websocket 认证,可按如下方式操作:
C# PuppeteerSharp
Browser API 的计费方式如何?
Browser API 的计费方式如何?
Browser API 计费简单:您仅需为通过 Browser API 传输的流量付费。Browser API 使用实例或时间不收取费用——仅按流量计费。不管使用哪个国家,流量按相同费率计费。由于按流量计费,您可能希望尽量减少流量。唯一例外是高级域名,每 GB 收费更高,因为 Bright Data 需要投入更多资源进行解锁。更多关于高级域名的信息请在 Browser API 配置页面查看。
如何降低 Browser API 的数据和带宽消耗?
如何降低 Browser API 的数据和带宽消耗?
是否允许在 Browser API 中输入密码?
是否允许在 Browser API 中输入密码?
Bright Data 致力于仅收集公开可用的数据。为了遵守这一承诺,Browser API 默认配置为阻止任何尝试登录账户的操作,从而禁用密码输入。此限制有助于确保不会抓取任何非公开数据——包括仅在登录后才能访问的数据。如需参考,请查看我们的 可接受使用政策 。在某些情况下,可能可以覆盖此默认限制。如果您需要例外,必须首先完成我们的 KYC(了解你的客户)流程。完成流程后,请直接联系我们的合规部门 compliance@brightdata.com 提交请求(您也可以在 KYC 流程中一并申请权限)。
如何在 Browser API 会话中保持相同的 IP 地址?
如何在 Browser API 会话中保持相同的 IP 地址?
Browser API 支持通过自定义 CDP 函数在多个浏览器会话中保持相同的 IP 地址。这允许您通过将连续请求关联到同一会话 ID 来重用同一个代理节点。有关实现细节和示例代码,请参阅我们的 会话持久化文档
将代理集成到自动化脚本与使用 Browser API 有何不同?
将代理集成到自动化脚本与使用 Browser API 有何不同?
1. 将代理集成到自动化脚本
- 您在自己的脚本中直接设置代理,使用工具如 Puppeteer、Playwright 或 Selenium。
- 您负责管理所有内容:浏览器设置、会话、扩展、反反爬挑战(CAPTCHA、指纹、请求头等)。
- 提供完全控制和灵活性,但您需自行维护和排查所有复杂问题,包括解封和可扩展性。
- 您将自动化脚本连接到运行在 Bright Data 云端的托管浏览器。
- Bright Data 处理基础设施、扩展、反反爬/解封(CAPTCHA、指纹等)和代理轮换。
- 您只需专注于抓取逻辑。对于复杂互动网站,更易于扩展。
- 如果希望强大抓取而无需维护或构建自己的反反爬解决方案,这是理想选择。
如何让 Browser API 抓取更快?
如何让 Browser API 抓取更快?
Browser API 的性能和优化由我们管理。我们一直致力于提升速度和可靠性。用户无法直接调整浏览器速度。在脚本中阻止不必要的网络请求(如图片、广告和分析脚本)可以减少数据使用,有时可能提升页面加载速度,但不保证更快加载。最可靠的好处是节省带宽。更多详情和示例代码,请参阅我们的 带宽优化指南。
如何知道 Browser API 使用的代理类型?
如何知道 Browser API 使用的代理类型?
默认情况下,Browser API 使用住宅代理(Residential proxies)。对于某些需要 KYC 的域名,如果需要合规,它可能会自动切换为数据中心代理(Datacenter proxies)。了解更多关于 KYC 和住宅代理访问的信息,请参阅 这里。
链接页面涵盖了住宅代理访问和 KYC 要求。关于 SSL 错误和其他代理类型的一些细节不适用于 Browser API。
如何使用 Playwright、Puppeteer 或 Selenium 连接 Browser API?
如何使用 Playwright、Puppeteer 或 Selenium 连接 Browser API?
要连接 Browser API,您需要区域用户名和密码。
- 对于 Playwright 和 Puppeteer,请使用 WebSocket (
wss://) 端点连接,主机为brd.superproxy.io,端口为9222。- 示例连接 URL:
wss://${AUTH}@brd.superproxy.io:9222
- 示例连接 URL:
- 对于 Selenium,请使用 HTTPS 端点连接,主机为
brd.superproxy.io,端口为9515。- 示例连接 URL:
https://${AUTH}@brd.superproxy.io:9515
- 示例连接 URL:
目前,连接 Browser API 的唯一方式是使用区域凭证(用户名和密码)的 WebSocket 或 HTTPS 端点。当前没有 REST API 连接方法。
代理 vs. Browser API,有何区别?我该使用哪个端点?
代理 vs. Browser API,有何区别?我该使用哪个端点?
- 普通代理网络:
您自行启动浏览器/进程,通过
brd.superproxy.io:33335路由流量,并使用brd-customer-<CID>-zone-<ZONE>:<PASSWORD>进行认证。 - Browser API(前称 Scraping Browser):
Bright Data 为您启动托管的云端 Chrome。您 不 启动
puppeteer.launch(),而是连接到远程浏览器:
我可以在单个 Browser API 会话中导航到多个 URL 吗?
我可以在单个 Browser API 会话中导航到多个 URL 吗?
可以 - Browser API 会话支持在同一域名内进行无限次导航。您可以在整个会话期间自由地在页面之间导航、点击链接、提交表单、滚动以及执行其他交互操作,只要所有导航都保持在同一域名内即可。若要在不同域名上启动抓取任务,您需要开始一个新会话。