什么是 Bright 数据 网页抓取工具?
什么是 Bright 数据 网页抓取工具?
Bright 数据 网页抓取工具是一种自动化工具,可帮助企业自动大规模采集各类线上公开数据,并大幅减少代理维护和开发方面的内部开销。网页抓取工具以结构化格式提供大量原始数据,并可与现有系统集成,立即用于竞争性的数据驱动决策。Bright 数据 已开发出数百种针对热门平台的网页抓取工具。
什么是 Web Scraper IDE?
什么是 Web Scraper IDE?
Web Scraper IDE 是一个集成开发环境。 IDE 可以是任何规模的,可轻松获取的公开网络数据库,您可:
- 在几分钟内构建抓取工具
- 轻松调试和诊断
- 快速投入生产
- 使用简单的 Javascript 编写浏览器脚本
使用网页抓取工具时的“输入”配置指什么?
使用网页抓取工具时的“输入”配置指什么?
“输入”配置就是您采集数据时需键入的一系列参数,以运行它们进行数据采集。这可能包括关键词、URL、搜索项目、产品 ID、ASIN、个人资料名称、入住日期和退房日期等。
使用网页抓取工具时的“输出”配置指什么?
使用网页抓取工具时的“输出”配置指什么?
“输出”配置就是根据您的输入参数从平台采集的数据。您可以 JSON/NDJSON/CSV/XLSX 的格式接收数据。
免费试用时,我可免费采集多少条记录?
免费试用时,我可免费采集多少条记录?
每次免费试用时,您可免费采集 100 条记录(注意:100 条记录并不意味着 100 次页面加载量)。
为何我收到的统计记录数大于输入参数中设置的记录数?
为何我收到的统计记录数大于输入参数中设置的记录数?
您收到的记录数总是高于您在输入配置中请求的记录数。
从社交媒体采集到的最常见数据点包括那些?
从社交媒体采集到的最常见数据点包括那些?
关注者数量、帖子的平均点赞次数、参与度、账户主题、受众的社交和人口统计特征、社交监听:关键词/品牌提及量、情绪、热门话题。
我可否从多个平台采集数据?
我可否从多个平台采集数据?
是的,我们可同时从各个网站大规模采集数据。
我可否在网页抓取工具中添加其他信息?
我可否在网页抓取工具中添加其他信息?
可以,您可向客户经理寻求协助,或者进入“报告问题”页面,提交与特定网页抓取工具相关的工单。然后请求在网页抓取工具中添加或删除字段。
什么是搜索型抓取工具?
什么是搜索型抓取工具?
如您不知道具体的 URL,则可搜索相关术语,然后根据该术语获取数据。
什么是发现型抓取工具?
什么是发现型抓取工具?
使用发现型抓取工具时,您可以直接输入 URL 并从相关页面采集所有数据。您无需指定具体的产品或关键词,即可收到数据。
我可否自行更改 IDE 中的代码?
我可否自行更改 IDE 中的代码?
可以,代码是用 JS 编写的,对于自管理抓取工具,您可根据自身需求更改代码。
可以通过哪些方式发起请求?
可以通过哪些方式发起请求?
我们通过 3 种方式供您发起请求:
- 通过 API 启动 - 常规请求、队列请求和替换请求。
- 手动启动。
- 定时模式
如何开始使用网页抓取工具?
如何开始使用网页抓取工具?
什么是队列请求?
什么是队列请求?
当您发送多个 API 请求时,“队列请求”则表示您希望在第一个请求完成后自动启动下一个请求,以此类推,其他请求也是如此。
什么是 CPM?
什么是 CPM?
CPM = 1000 次页面加载
在构建抓取工具时,哪些事件会被计费?
在构建抓取工具时,哪些事件会被计费?
计费事件如下所示:
navigate()request()load_more()- (后期)媒体文件下载
如何确认有人正在帮我开发所要求的新的网页抓取工具?
如何确认有人正在帮我开发所要求的新的网页抓取工具?
您将收到一封电子邮件,告知开发人员正为您开发新的网页抓取工具,当您的抓取工具准备就绪后,您将收到通知。您还可以在控制面板上查看请求状态: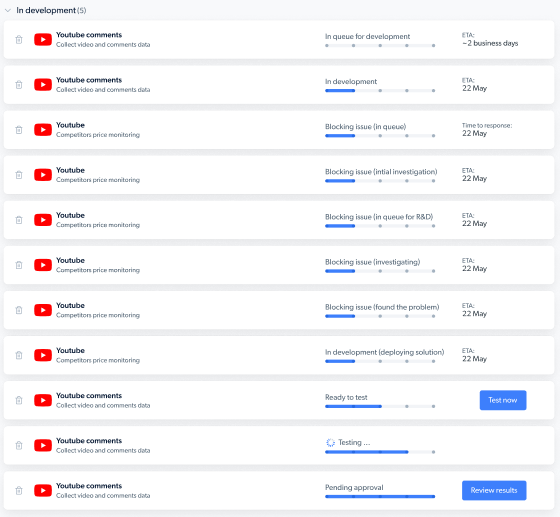
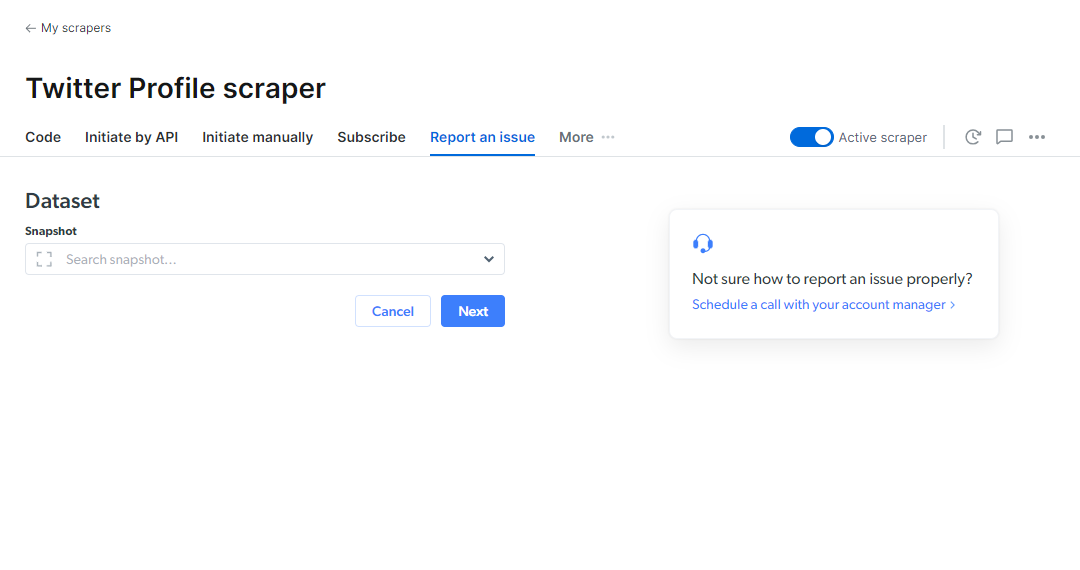
如何在 Web scraper IDE 上报告问题?
如何在 Web scraper IDE 上报告问题?
您可以使用此表单来沟通您在平台、抓取工具或数据集结果方面遇到的任何问题。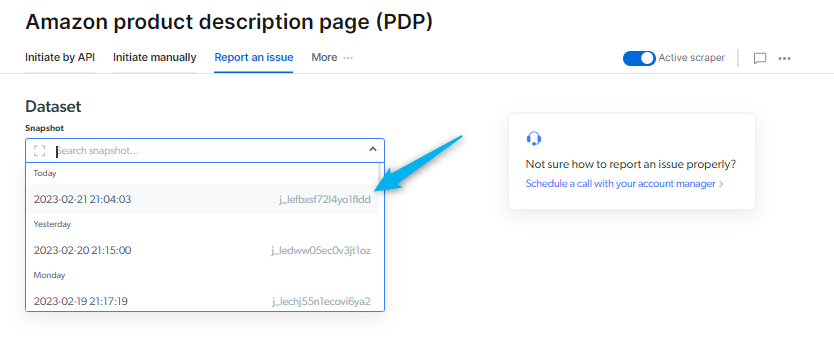
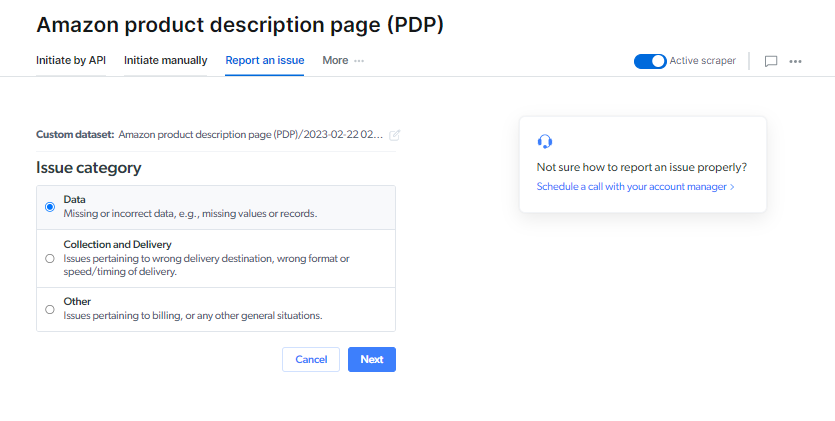
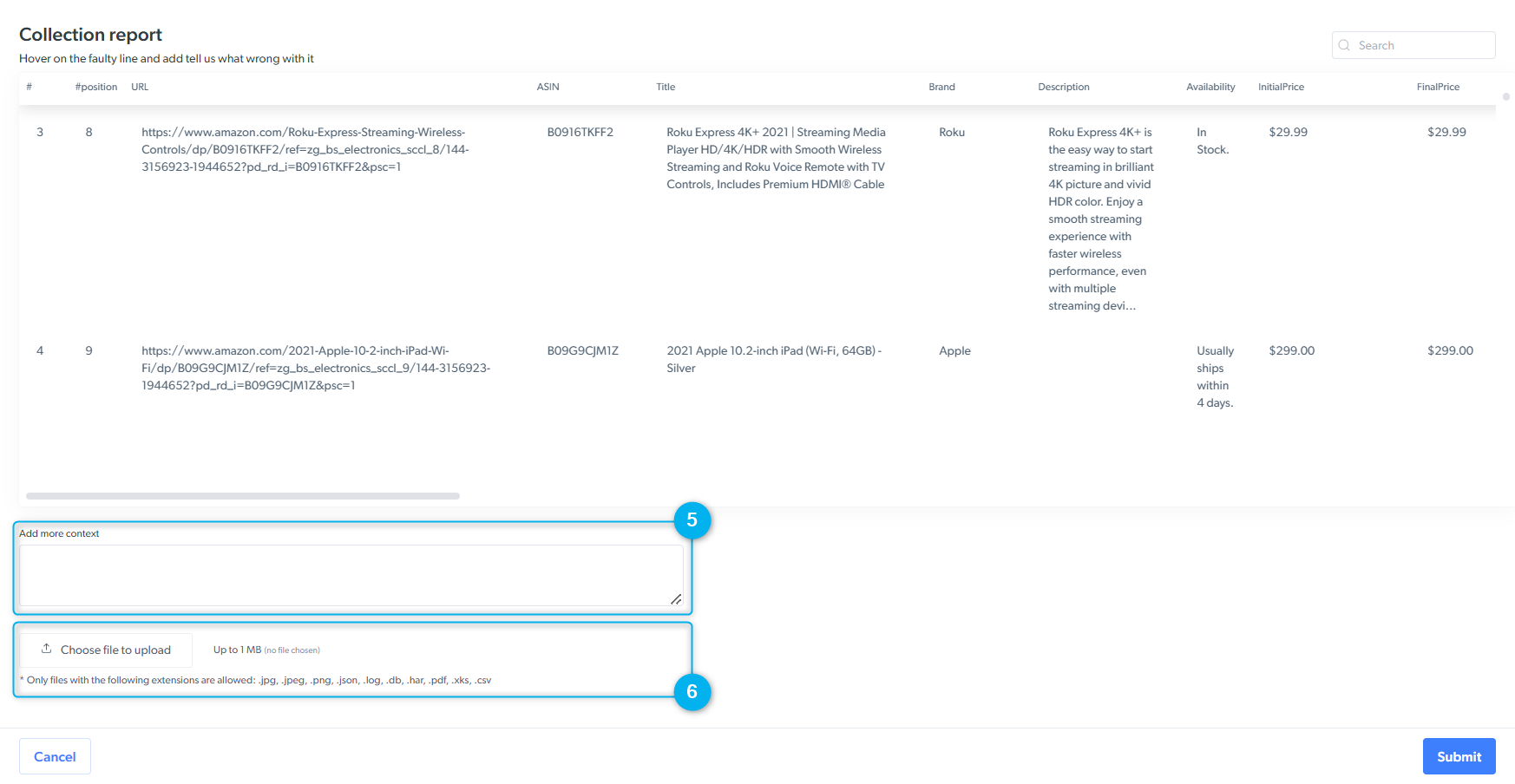
我们会根据所选问题类型将您的工单分配给各个部门。 请务必选择最相关的问题类型。*
1
选择作业 ID:已发布的数据集
2
选择问题类型
数据
数据
此选项仅适用于托管型抓取工具。工单将直接发送至您的抓取工具工程师。
- 字段缺失
- 记录缺失
- 值缺失
- 解析问题:数据集结果不正确
采集和交付
采集和交付
此类工单将发送至我们的支持人员。
- 交付不完整:交付期间出现问题
- 抓取工具运行缓慢:抓取工具采集速度慢或被卡住
其他
其他
此类工单将发送至您的客户经理。
- UI 问题:UI 无法正常运行
- 产品问题:使用 Web Scraper 产品时遇到的一般性问题
- 其他问题
3
(解析问题)使用红色“故障”图标指明哪些采集结果不正确。
4
(解析问题)输入您期望收到的采集结果
5
描述问题,并填写用于采集数据的 URL
6
如有需要,请附上图片以更直观地展示您报告的问题。
我更新了托管型抓取工具的输入/输出架构。 我可否在 Bright数据 更新我的抓取工具的过程中继续使用它?
我更新了托管型抓取工具的输入/输出架构。 我可否在 Bright数据 更新我的抓取工具的过程中继续使用它?
更新输入/输出架构后,需要更新抓取工具以匹配新架构。如果您在抓取工具尚未更新完毕期间运行它,则会看到“输入/输出架构不兼容”的错误提示。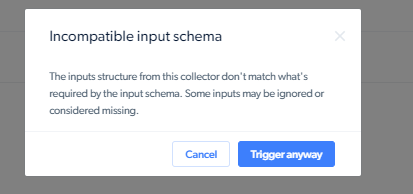
如果您想在忽略架构更改的情况下启动抓取工具,则可点击 UI 上的“仍然触发 (Trigger anyway)” 按钮。如想通过 API 启动,您可输入
- 通过 UI
- 通过 API
如果您想在忽略架构更改的情况下启动抓取工具,则可点击 UI 上的“仍然触发 (Trigger anyway)” 按钮。如想通过 API 启动,您可输入
- 输出架构不兼容:
override_incopatible_schema=1 - 输入架构不兼容:
override_incopatible_input_schema=1
如何调试实时抓取工具?
如何调试实时抓取工具?
我们会在虚拟作业记录中存储最近发生的 1000 个错误,这样您就可以查看错误的输入示例(可通过 CP 按钮在 IDE 中查看这些错误)。客户应该知道哪些输入是错误的,因为他们已收到“错误”的响应。您可在 IDE 中通过手动方式重新运行它们,查看会发生的情况。这就好比在解锁器运行出错时提供 CURL 请求示例一样。
如果在使用网页抓取工具时遇到问题,我该怎么办?
如果在使用网页抓取工具时遇到问题,我该怎么办?
请转到 Bright 数据 的控制面板,点击“报告问题”。 我们的 14 位开发人员每天都会监控用户提交的各种工单,一旦您上报问题,系统会自动将您的工单分配给其中一位开发人员。 请务必详细描述遇到的问题,如不确定所遇到的问题,请联系您的客户经理。报告问题后,您无需再执行其他操作,您将会收到一封电子邮件,确认问题已被报告。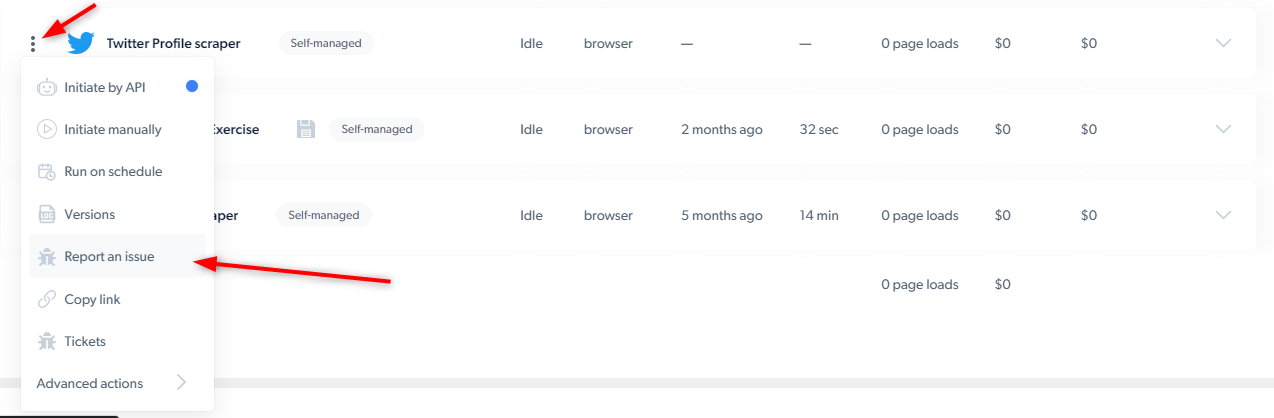
“报告问题”时,我该在报告中包含哪些信息?
“报告问题”时,我该在报告中包含哪些信息?
请在报告问题时提供以下信息:
- 选择遇到的问题类型(例如:获得错误的结果/数据点缺失/结果从未加载/交付问题/ UI 问题/抓取工具运行缓慢/IDE 问题/其他)
- 请详细描述您遇到的问题
- 您还可以上传相关文件,展示遇到的问题。
What is a 数据 Collector?
What is a 数据 Collector?
In the past, we referred to all of our scraping tools as “Collectors.” A Collector is essentially a web scraper that consists of both interaction code and parser code. It can operate as an HTTP request or in a real browser, with all requests routed through our unlocker network to prevent blocking.Over time, we developed a 数据set Unit that builds on top of one or more Collectors. For example, with a single Collector (direct request), you can scrape a specific URL—such as a product page from an e-commerce site—and receive the parsed data. In more complex scenarios, multiple Collectors can work together, such as when discovering and scraping categories, followed by collecting data on every product within those categories.
How to Create a 数据 Collector?
How to Create a 数据 Collector?
You have a few options to create and configure a 数据 Collector:
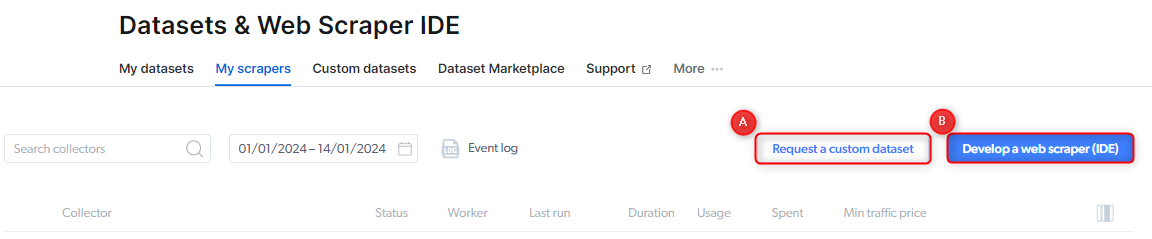
- Using the Web Scraper IDE: You can design and structure your parser as individual Collectors or as a single Collector with multiple steps. To get started:
- Click on the “Web 数据 Collection” icon on the right.
- Navigate to the “My Scrapers” tab.
- Select the “Develop a Web Scraper (IDE)” button.
- Requesting a Custom 数据set: If you prefer us to handle it, you can request a custom dataset, and we’ll create the 数据 Collectors needed to deliver it. To do this, click on the “Request 数据集” button under the “My 数据集” tab and choose the option that best suits your needs. Start here: Request a Custom 数据set