什么是 Bright Data Web Scraper?
什么是 Bright Data Web Scraper?
Bright Data Web Scraper 是自动化工具,使企业能够在大规模下自动收集各种公开在线数据,同时大幅减少内部代理维护和开发成本。Web Scraper 能够以结构化格式提供大量原始数据,并与现有系统集成,可立即用于竞争性数据驱动决策。Bright Data 已经开发了数百个针对热门平台定制的 Web Scraper。
什么是 Web Scraper IDE?
什么是 Web Scraper IDE?
Web Scraper IDE 是一个集成开发环境。IDE 将公共网页数据轻松置于你的指尖,你可以:
- 在几分钟内构建你的抓取器
- 轻松调试和诊断
- 快速投入生产
- 使用简单的 JavaScript 进行浏览器脚本操作
使用 Web Scraper 时,什么是“输入”?
使用 Web Scraper 时,什么是“输入”?
在收集数据时,你的“输入”是运行抓取所需的参数。这可以包括关键词、URL、搜索项目、产品 ID、ASIN、个人资料名称、入住和退房日期等。
使用 Web Scraper 时,什么是“输出”?
使用 Web Scraper 时,什么是“输出”?
输出是你根据输入参数从平台收集的数据。你将以 JSON/NDJSON/CSV/XLSX 格式收到数据。
免费试用包含多少条记录?
免费试用包含多少条记录?
每次免费试用包含 100 条记录(注意:100 条记录不等于 100 页加载)。
为什么收到的统计记录多于输入记录?
为什么收到的统计记录多于输入记录?
你收到的记录总是多于请求的输入记录数。
社交媒体中最常收集的数据点是什么?
社交媒体中最常收集的数据点是什么?
粉丝数量、帖子平均点赞数、互动水平、账号主题、受众社交与人口统计特征、社交聆听:关键词/品牌提及、情感、病毒趋势。
我可以从多个平台收集数据吗?
我可以从多个平台收集数据吗?
可以,我们可以同时从大量网站收集数据。
我可以向我的 Web Scraper 添加额外信息吗?
我可以向我的 Web Scraper 添加额外信息吗?
可以,你可以向你的客户经理寻求帮助,或者通过选择“报告问题”打开相关 Web Scraper 的工单。然后请求添加或移除字段。
什么是搜索抓取器?
什么是搜索抓取器?
当你不知道具体 URL 时,可以搜索一个词,并基于该词获取数据。
什么是发现抓取器?
什么是发现抓取器?
使用发现抓取器,你输入 URL,并收集该页面的所有数据。无需指定具体产品或关键词即可获得数据。
我可以自行更改 IDE 中的代码吗?
我可以自行更改 IDE 中的代码吗?
可以,代码是 JS 语言,对于自主管理的抓取器,你可以根据需求进行修改。
有哪些方式发起请求?
有哪些方式发起请求?
我们有 3 种发起请求的方式:
- 通过 API 发起 - 普通请求、排队请求和替换请求
- 手动发起
- 定时模式
什么是排队请求?
什么是排队请求?
当你发送多个 API 请求时,“排队请求”意味着希望下一次请求在前一次请求完成后自动开始,以此类推。
什么是 CPM?
什么是 CPM?
CPM = 1000 页加载
构建抓取器时,哪些操作属于计费事件?
构建抓取器时,哪些操作属于计费事件?
计费事件:
navigate()request()load_more()- (稍后)媒体文件下载
如何确认有人正在开发我请求的新 Web Scraper?
如何确认有人正在开发我请求的新 Web Scraper?
你会收到电子邮件,告知开发者正在开发你的新 Web Scraper,并在抓取器准备好时通知你。请求状态也可在你的仪表板查看: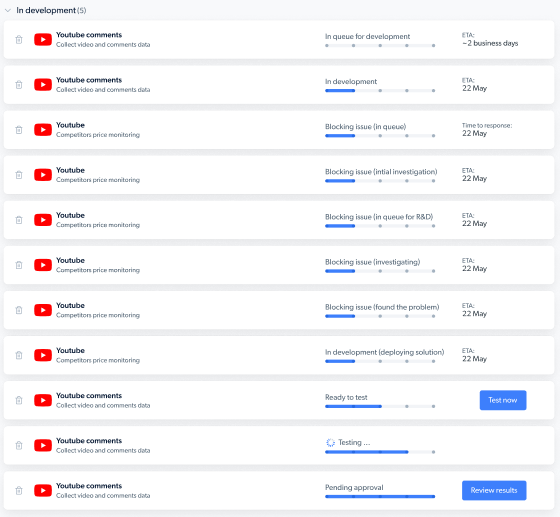
如何报告 Web Scraper IDE 的问题?
如何报告 Web Scraper IDE 的问题?
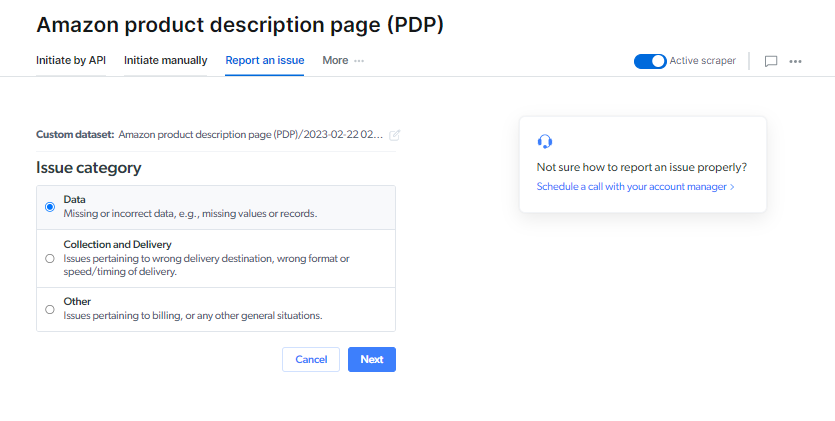
你可以使用此表单提交任何平台、抓取器或数据集结果的问题。
工单将根据所选问题类型分配至不同部门。请确保选择最相关的类型。*
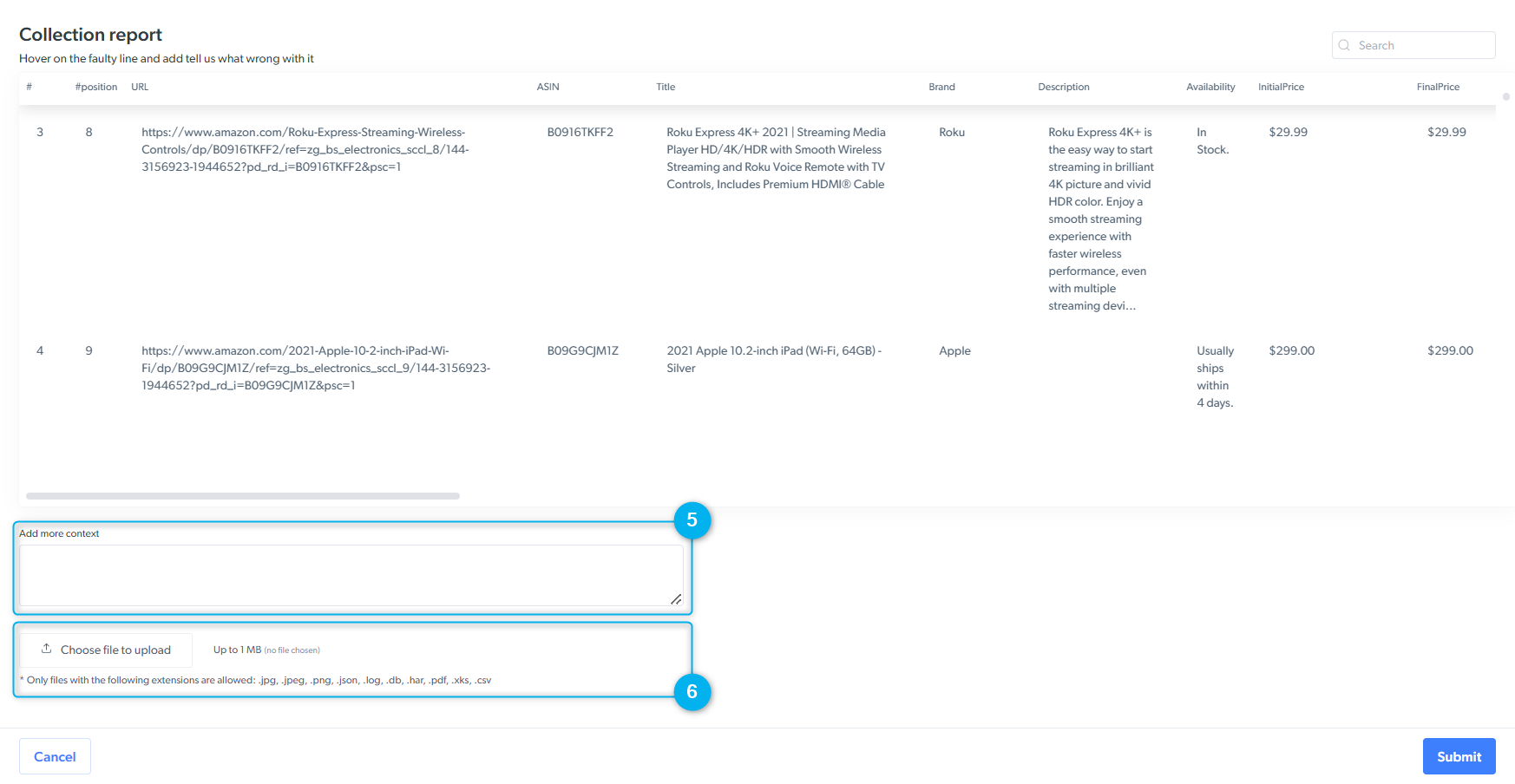
我更新了托管抓取器的输入/输出架构。在 Bright Data 更新抓取器时,我可以使用它吗?
我更新了托管抓取器的输入/输出架构。在 Bright Data 更新抓取器时,我可以使用它吗?
当输入/输出架构更新时,抓取器需要更新以匹配新架构。如果抓取器正在处理且尚未更新,你会看到“输入/输出架构不兼容”错误。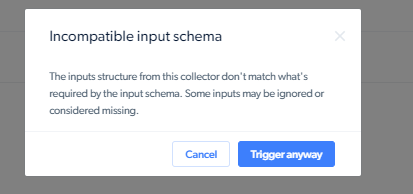
如果希望忽略架构更改发起抓取,可以在 UI 点击“仍然触发”。API 上可以添加:
- 通过 UI
- 通过 API
如果希望忽略架构更改发起抓取,可以在 UI 点击“仍然触发”。API 上可以添加:
- 输出架构不兼容:
override_incompatible_schema=1 - 输入架构不兼容:
override_incompatible_input_schema=1
我如何调试实时抓取器?
我如何调试实时抓取器?
我们在虚拟作业记录中存储最近 1000 个错误,以便你可以查看错误的输入示例(IDE 中有 CP 按钮查看错误)。客户应已知哪些输入出错,因为他们收到了“错误”响应。你可以在 IDE 中手动重新运行这些输入,查看发生了什么。就像在阻塞器表现异常时提供 CURL 请求示例。
如果遇到 Web Scraper 问题,我该怎么办?
如果遇到 Web Scraper 问题,我该怎么办?
从 Bright Data 控制面板选择“报告问题”。一旦报告问题,将自动分配工单给我们 14 位每天监控工单的开发人员。请提供问题细节,如果不确定,请联系客户经理。一旦报告问题,无需其他操作,并会收到确认邮件。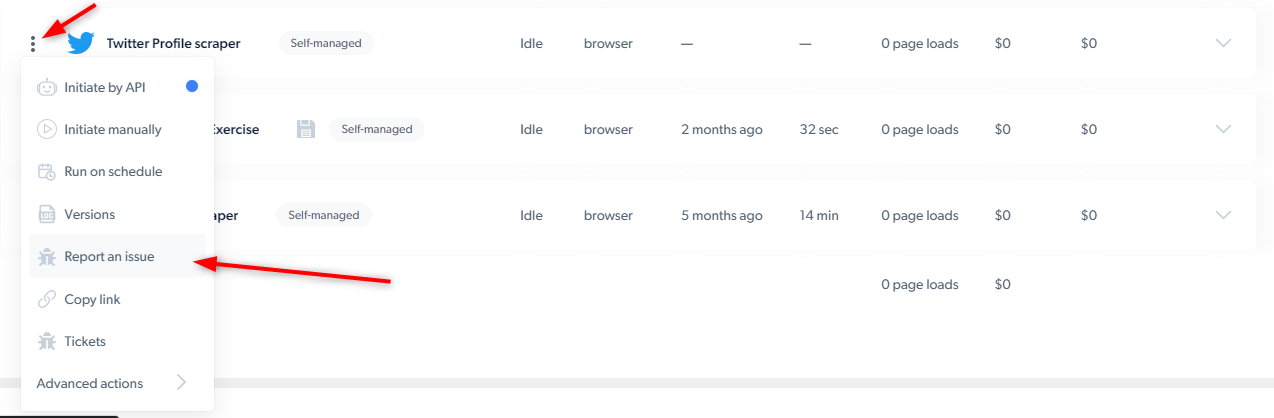
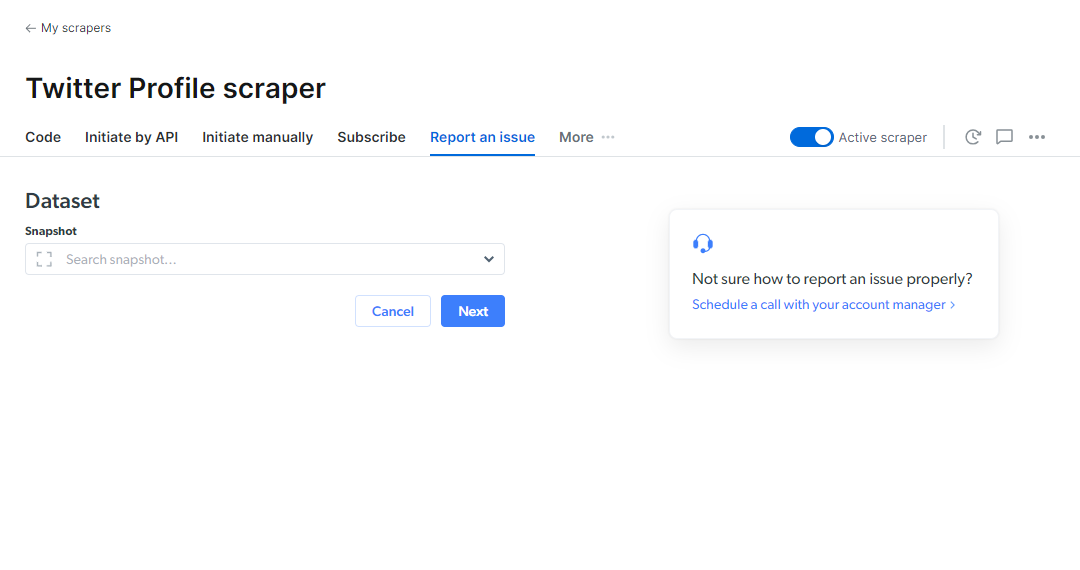
报告问题时,应提供哪些信息?
报告问题时,应提供哪些信息?
报告问题时,请提供以下信息:
- 选择问题类型(例如:结果错误/数据点缺失/结果未加载/交付问题/UI 问题/抓取器慢/IDE 问题/其他)
- 详细描述问题
- 可上传文件描述问题
什么是数据采集器(Data Collector)?
什么是数据采集器(Data Collector)?
过去,我们将所有抓取工具称为“Collector”。Collector 本质上是由交互代码和解析器代码组成的 Web Scraper。它可以以 HTTP 请求方式或在真实浏览器中运行,所有请求都通过我们的解锁网络以防被封。随着时间发展,我们开发了数据集单元(Dataset Unit),可基于一个或多个 Collector 构建。例如,通过单个 Collector(直接请求),你可以抓取特定 URL(如电商网站产品页),并获取解析数据。在更复杂场景中,多个 Collector 可协作,如先发现和抓取类别,再收集该类别下每个产品的数据。
如何创建数据采集器?
如何创建数据采集器?
你有几种创建和配置 Data Collector 的方式:
- 使用 Web Scraper IDE: 你可以将解析器设计为单独 Collector 或多步骤单 Collector。开始方法:
- 点击右侧“Web Data Collection”图标
- 转到“My Scrapers”标签
- 点击“Develop a Web Scraper (IDE)”按钮
- 请求自定义数据集: 如果希望我们处理,可请求自定义数据集,我们将创建所需 Data Collector。 点击“My Datasets”下的“Request Datasets”按钮,选择最适合的选项。 开始这里: 请求自定义数据集
有系统限制吗?
有系统限制吗?
我们限制 100 个并行运行作业。超过 100 个作业时,额外作业将排队等待先前作业完成。
如何使用 AI 代码生成器?
如何使用 AI 代码生成器?
概述
此功能旨在为目标网站生成定制代码模板。只需输入目标 URL,我们会自动生成可编辑或运行的代码模板。工作原理
输入目标 URL 并点击“生成代码”。代码准备好后会显示在 IDE 标签中,无需等待 AI 处理完成。代码准备好后你会收到邮件通知。\
此功能旨在为目标网站生成定制代码模板。只需输入目标 URL,我们会自动生成可编辑或运行的代码模板。工作原理
输入目标 URL 并点击“生成代码”。代码准备好后会显示在 IDE 标签中,无需等待 AI 处理完成。代码准备好后你会收到邮件通知。\
此功能适用于 PDP(产品详情页)URL——已知目标 URL 时生成相应解析器代码。不适合“发现”场景。
触发抓取后,数据快照可保存多久?
触发抓取后,数据快照可保存多久?
结果数据在收集后可下载 16 天。为避免过期,请在 16 天内下载,或配置自动交付至存储。