IDE
这里是您编写 JavaScript 代码的地方。了解更多内容请参阅 网页爬取基础。
- 我们爬虫工程师构建的模板代码示例。
- 当您想从多个页面收集数据时,添加阶段非常有用。例如,如果您想收集 Amazon 搜索结果页面的所有产品及其详细信息,您可以在第一阶段导航搜索结果页面以收集所有产品 URL,并将其传递到第二阶段导航每个产品页面。
- 可使用
next_stage和run_stage命令在阶段之间交互。
- 输入 (Input):定义输入参数,并使用输入集运行测试(预览)
- 输出 (Output):收集到的数据列表
- 子阶段 (Children):下一阶段的输入集列表
- 运行日志 (Run log):代码执行日志
- 浏览器控制台 (Browser console):爬虫浏览器控制台日志 [浏览器 > 开发者工具 > ‘控制台’ 标签]
- 浏览器网络 (Browser network):爬虫浏览器网络日志 [浏览器 > 开发者工具 > ‘网络’ 标签]
- 最近错误 (Last errors):最新错误信息列表
- 添加输入参数:定义输入参数,包括名称和类型
- 添加另一个输入:为测试添加输入集的值
- 预览:使用选定的输入集运行测试
- 错误模式 (Error mode):设置爬虫在出现错误时的行为
- 截图 (Take screenshot):在预览测试过程中截取页面截图,以便查看加载的页面
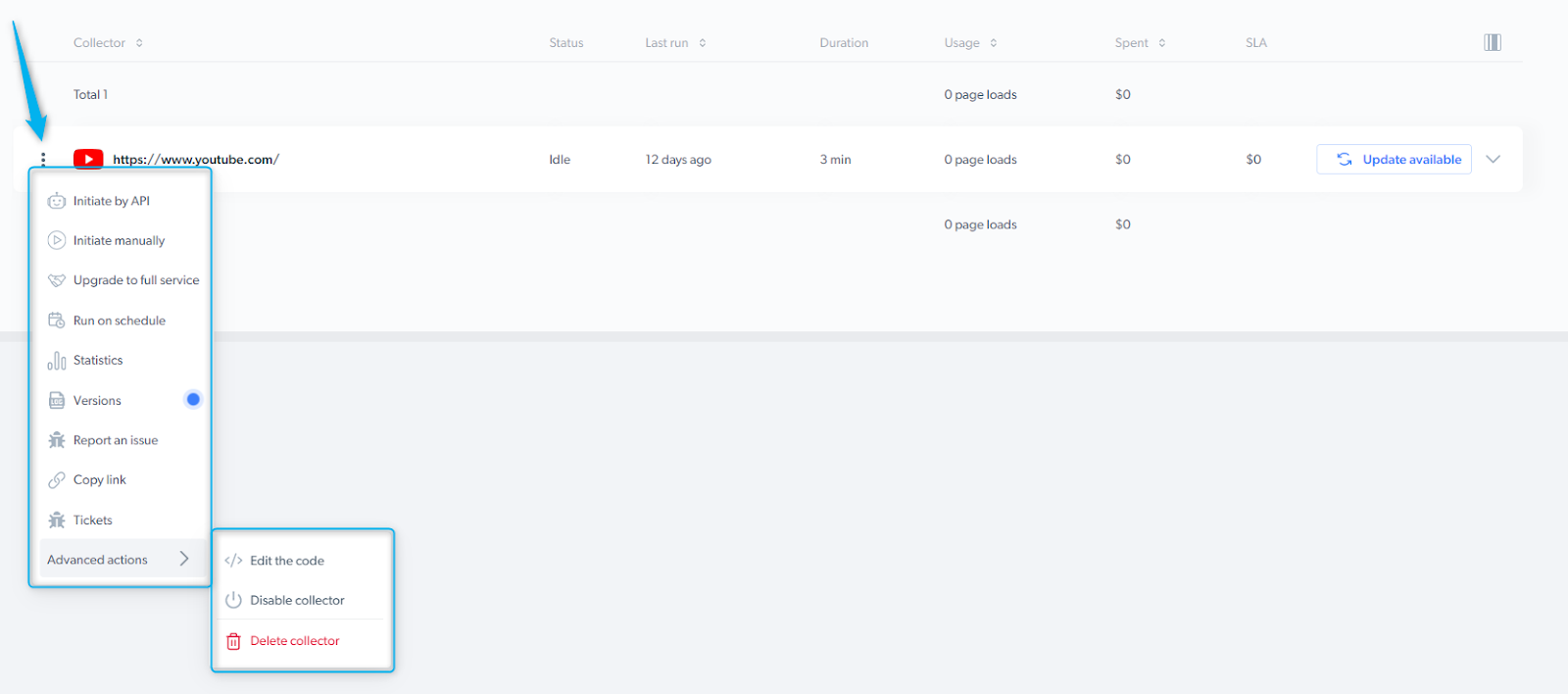
仪表盘 - 爬虫操作菜单
爬虫操作菜单允许对爬虫执行不同操作。- 通过 API 启动 - 无需进入控制面板即可开始数据收集
- 手动启动 - Bright Data 控制面板可轻松开始数据收集
- 按计划运行 - 精确选择何时收集所需数据
- 版本 - 查看爬虫修改的版本
- 报告问题 - 使用此表单反馈平台、爬虫或数据集结果的问题
- 复制链接 - 复制爬虫链接与同事共享
- 工单 - 查看工单状态
- 高级选项:
- 编辑代码 - 在 IDE 中编辑爬虫代码
- 禁用爬虫 - 临时禁用爬虫,如有需要可重新启用
- 删除爬虫 - 永久删除爬虫