IDE 面板
IDE 面板用于编写并测试爬虫代码。下方各标注组件对应 IDE 界面中的不同区域。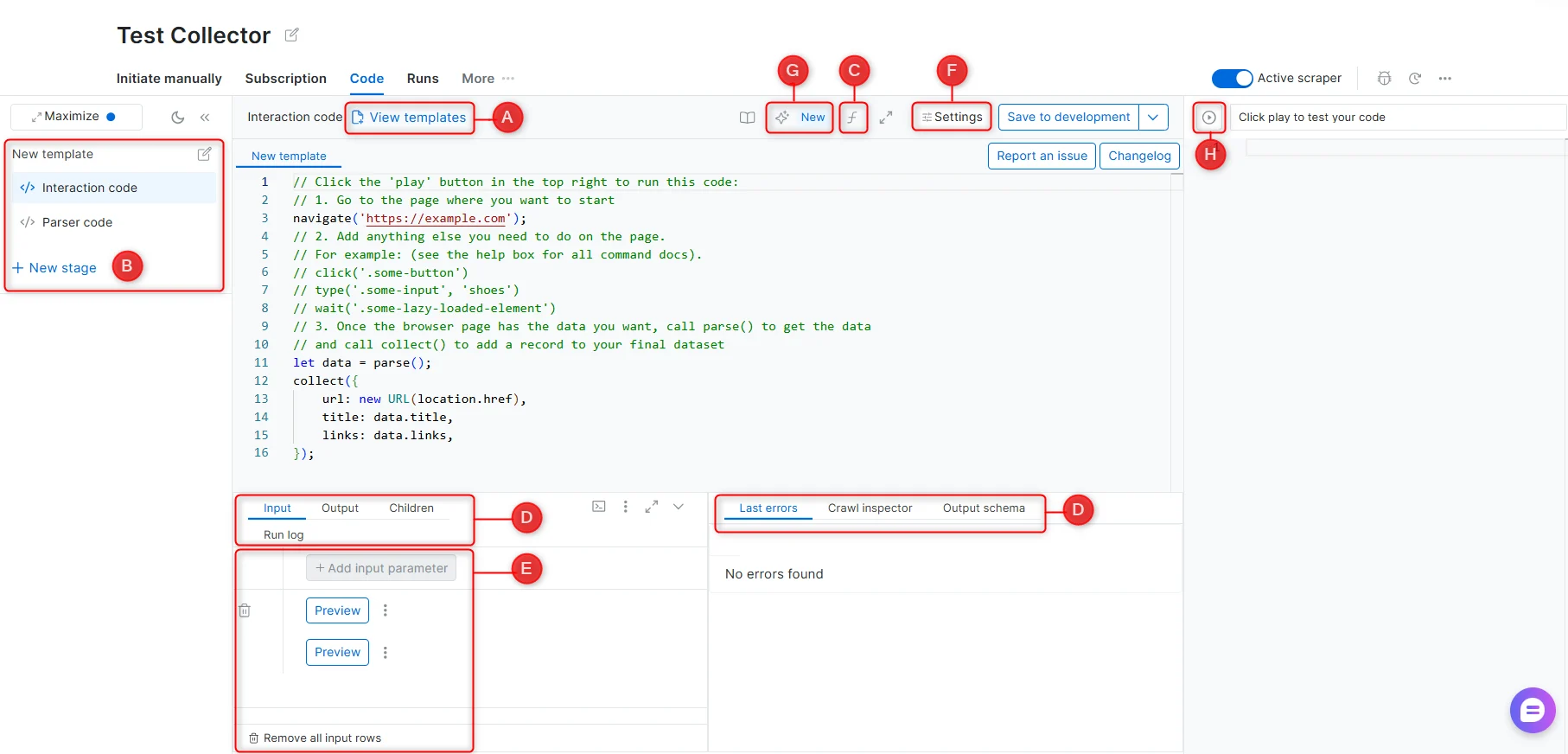
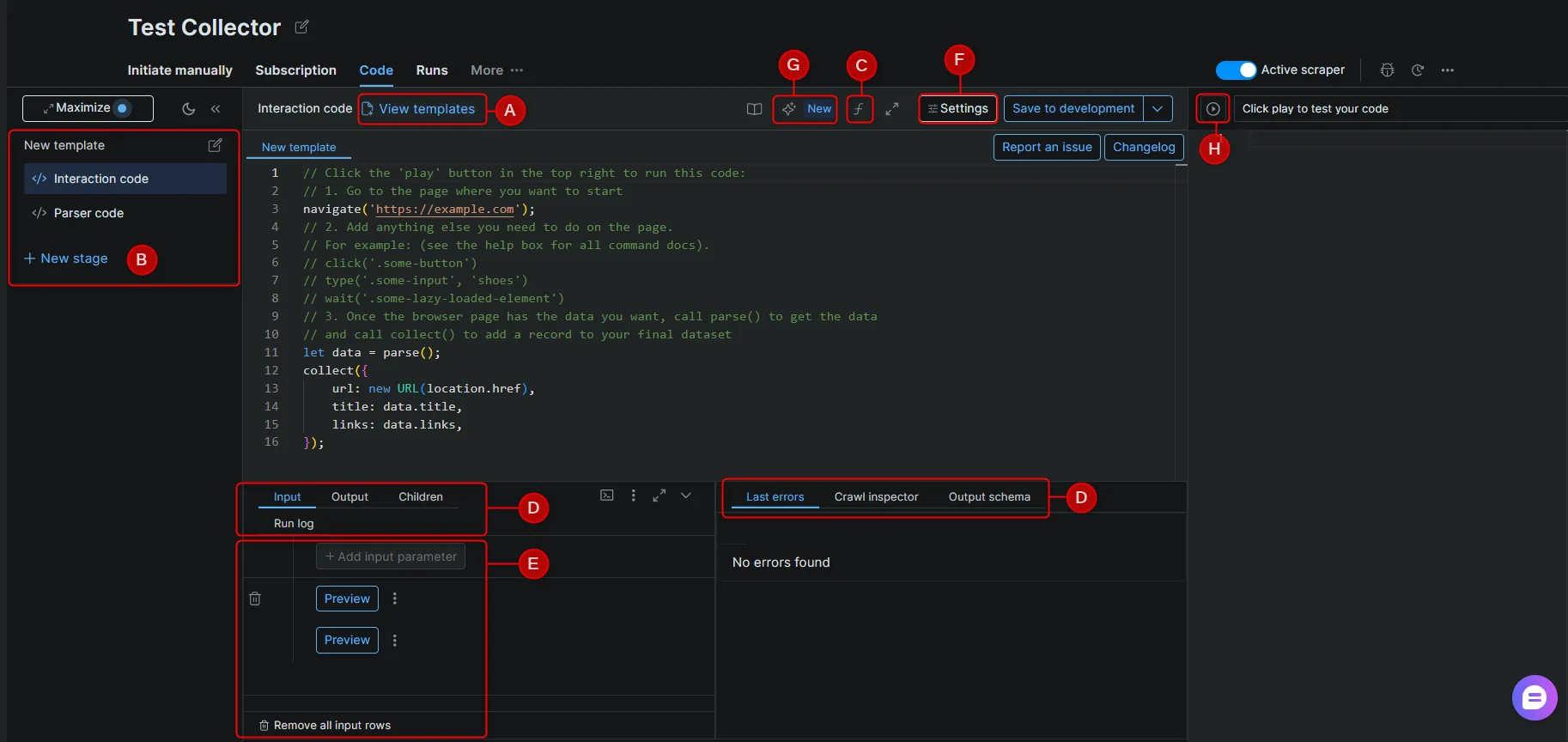
A - Templates(模板)
由 Bright Data 工程团队编写的预置爬虫代码库,覆盖常见网站与抓取模式。模板是起点;如果目标网站的结构已发生变化,可能需要做相应调整。B - Stages(阶段)
阶段使爬虫能够按顺序在多个步骤中运行。每个阶段通过next_stage() 或 run_stage() 接收上一阶段的输入。当抓取需要在多种页面类型之间导航时(例如,从列表页采集 URL,再从每个 URL 抽取详情),请使用阶段。
完整命令参考请参阅 Scraper Studio 函数。
C - Functions reference(函数参考)
IDE 内置的参考面板,列出所有可用的抓取函数,并附带说明与示例。参阅 交互函数 与 解析器函数。
D - Debugging tabs(调试标签)
| 标签 | 说明 |
|---|---|
| Input | 定义输入参数并选择一个输入集,用于预览测试 |
| Output | 预览运行后爬虫返回的结构化数据 |
| Children | 传递给多阶段爬虫下一阶段的输入集 |
| Run log | 最近一次预览运行的完整代码执行日志 |
| Browser network | 浏览器级网络活动日志(等同于 DevTools > Network 标签) |
| Last errors | 最近的错误信息,包括错误码与受影响的输入(保留最近 1,000 条) |
| Crawl inspector | 批处理作业中抓取的全部页面,含成功与失败。对于多阶段爬虫,可使用 Search for children 查看每个父输入产生的页面 |
| Output schema | 爬虫输出的字段名称与数据类型。点击 Edit Schema 可修改输入或输出 schema |
E - Input(输入)
| 控件 | 说明 |
|---|---|
| Add input parameter | 通过名称与类型定义新的输入参数 |
| New input | 向输入集中添加一个用于测试的值 |
| Preview | 使用所选输入集运行爬虫 |
F - Settings(设置)
| 设置项 | 说明 |
|---|---|
| Worker | 为该爬虫选择 Browser Worker 或 Code Worker |
| Error mode | 定义爬虫在出现错误时的行为 |
| Take screenshot | 在预览运行期间对加载的页面进行截图 |
| Worker per stage | 为每个阶段分配不同的 worker 类型,而非为整个爬虫使用单一 worker |
选择 Browser worker 与 Code worker 的建议请参阅 Worker 类型。
G - Self-Healing Tool(自我修复工具)
AI 驱动的代码重构。接受自然语言提示词,无需手动编辑代码即可修复错误或修改输入/输出字段。参阅 Self-Healing 工具。
H - Preview(预览)
针对当前所选输入集运行爬虫。结果显示在 Output 调试标签中。仪表盘 - 爬虫操作菜单
仪表盘在 My Scrapers 中列出您所有的爬虫。每个爬虫都有一个操作菜单,包含以下选项:| 操作 | 说明 |
|---|---|
| Initiate manually | 直接从 UI 启动一次数据采集 |
| Initiate by API | 通过 API 以编程方式触发数据采集 |
| Run on schedule | 配置周期性采集,按天、按周或自定义间隔运行 |
| Delivery preferences | 为已完成的作业设置输出格式与交付目的地 |
| Code | 在 IDE 中打开该爬虫 |
| Tickets | 查看该爬虫的待处理工单 |
| Report an issue | 提交平台、爬虫或数据质量问题的反馈 |