什么是 Scrapers?
什么是 Scrapers?
谁可以从使用 Scrapers 中受益?
谁可以从使用 Scrapers 中受益?
我如何开始使用 Scrapers?
我如何开始使用 Scrapers?
不同爬虫之间有什么区别?
不同爬虫之间有什么区别?
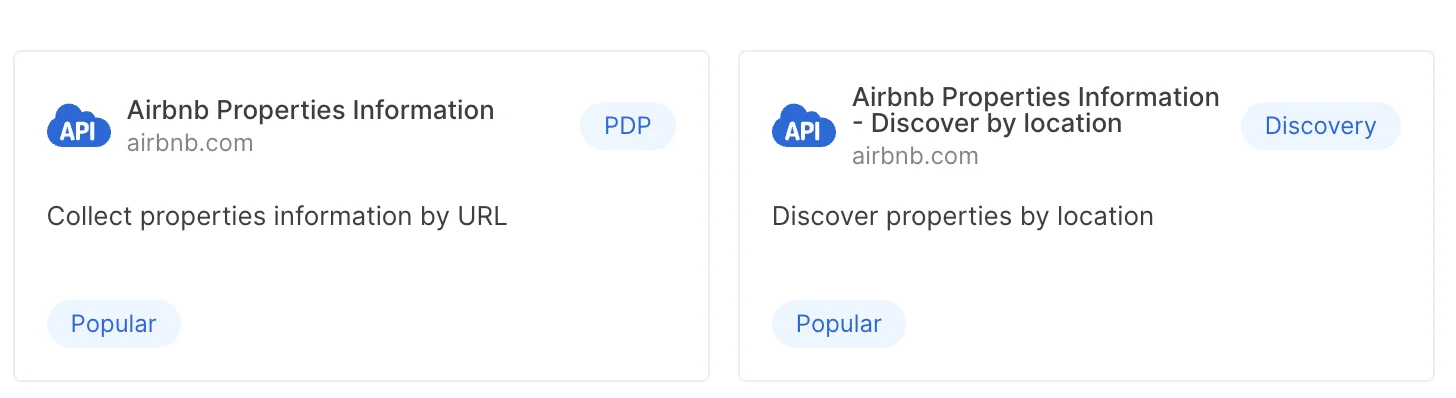
- PDP
这些爬虫需要 URL 作为输入。PDP 爬虫可从网页提取详细的产品信息,如规格、价格和功能 - Discovery/ Discovery+PDP
Discovery 爬虫允许您通过搜索、分类、关键词等方式探索并发现新实体/产品。
为什么同一域名有不同的 Discovery API?
为什么同一域名有不同的 Discovery API?
我如何使用 Scrapers 进行认证?
我如何使用 Scrapers 进行认证?
Authorization 头中包含 API 密钥,如下所示:Authorization: Bearer YOUR_API_KEY。我如何自定义请求并触发它?
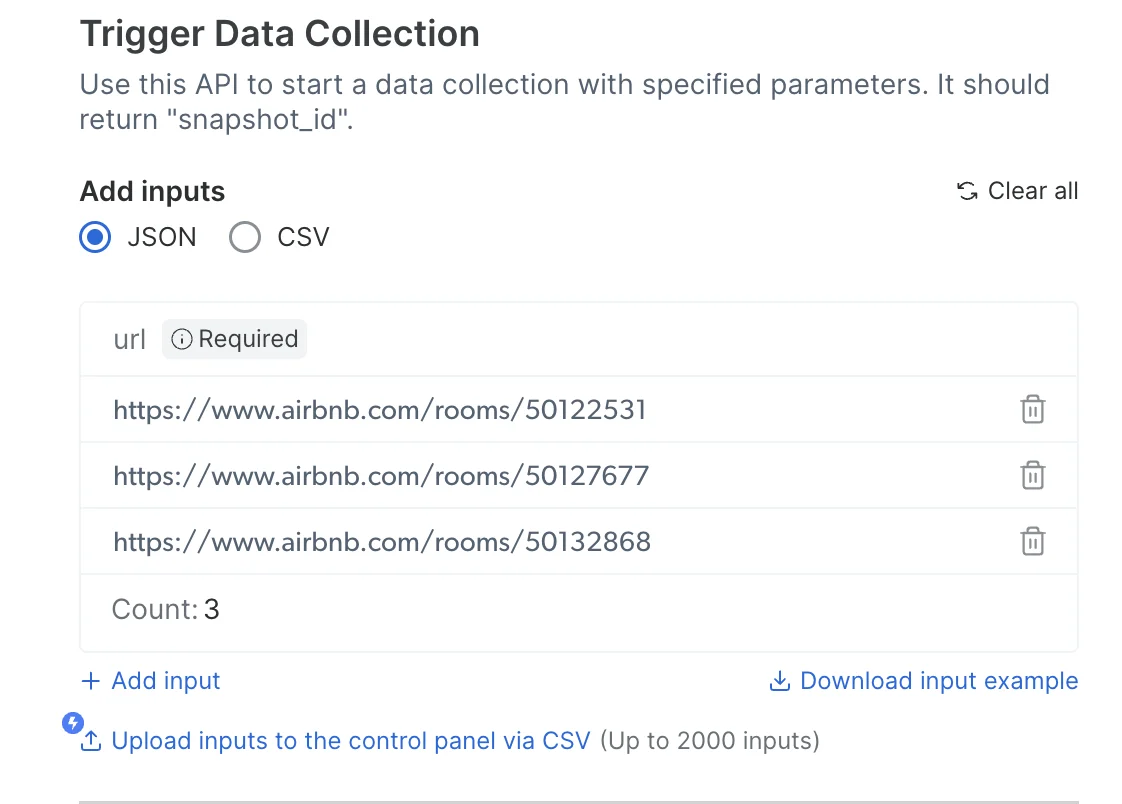
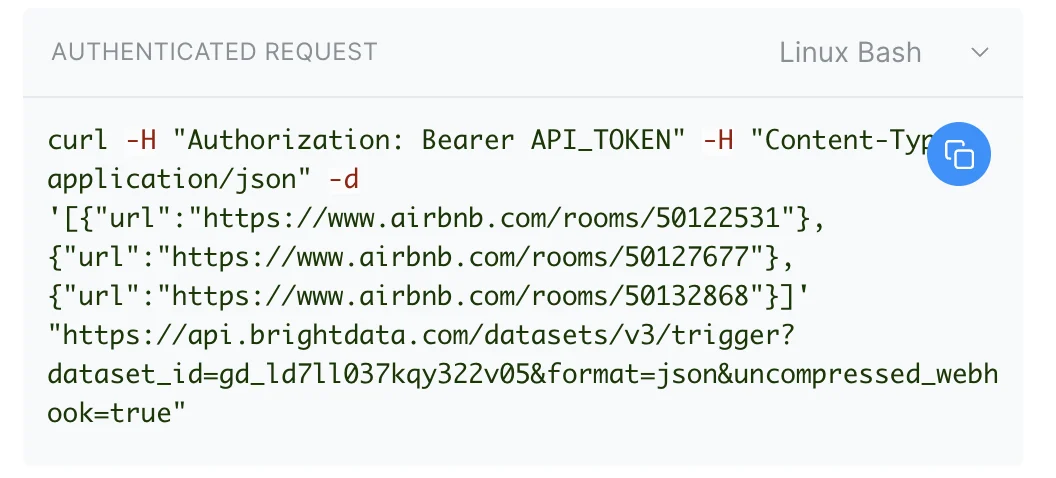
我如何自定义请求并触发它?
是否提供免费试用?
是否提供免费试用?
我如何测试 API?
我如何测试 API?

选择首选的交付方式
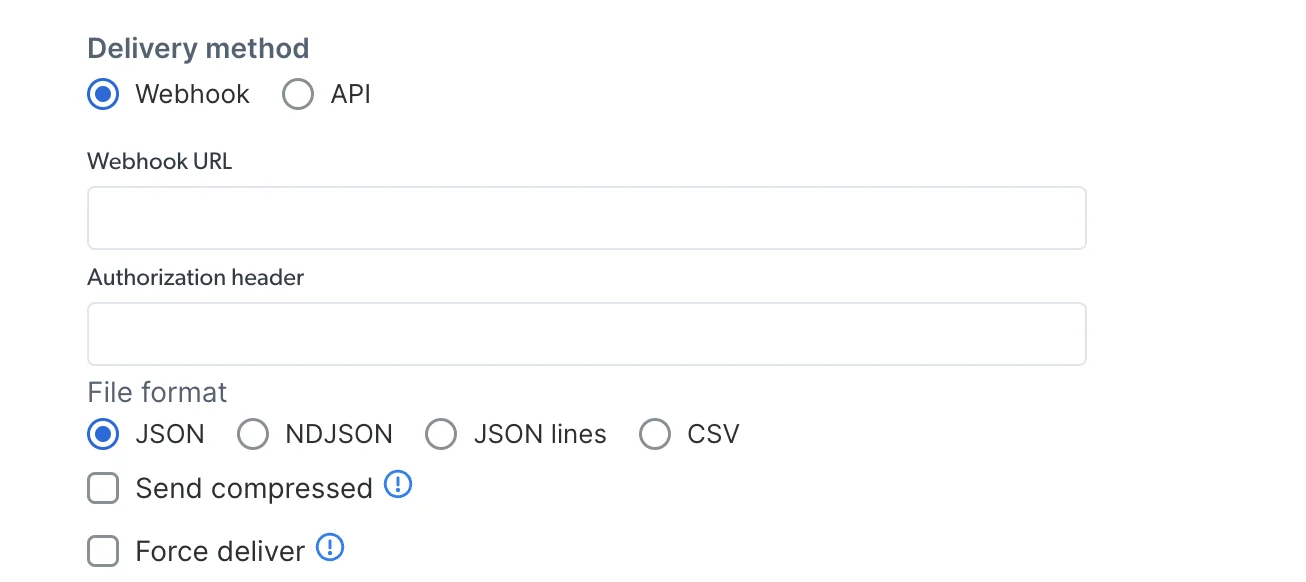
S3、GCP、pubsub 等)填写所需凭证和信息,收集结束后复制并运行代码复制代码并在客户端运行
Scrapers 支持哪些数据格式?
Scrapers 支持哪些数据格式?
JSON、NDJSON、JSONL 和 CSV。请在请求参数中指定所需格式。Scrapers 的收费标准是什么?
Scrapers 的收费标准是什么?
如果我的 API 密钥过期,我该怎么办?
如果我的 API 密钥过期,我该怎么办?


Scraper API 如何管理大规模数据提取任务?
Scraper API 如何管理大规模数据提取任务?
我如何升级我的订阅计划?
我如何升级我的订阅计划?
Scraper API 针对哪些特定用例进行了优化?
Scraper API 针对哪些特定用例进行了优化?
Scrapers 的速度有多快?
Scrapers 的速度有多快?
我如何取消 API 调用?
我如何取消 API 调用?
notify URL 和 webhook URL 配置有什么区别?
notify URL 和 webhook URL 配置有什么区别?
- 通常用于异步通信。
- 当任务完成或事件发生时,系统会向指定 URL 发送通知。
- 通知通常比较轻量,不包含详细数据,但可能提供参考或状态以便进一步操作(例如:“作业完成,请检查日志详情”)。
- 也用于异步通信,但更以数据为中心。
- 当特定事件发生时,系统会将详细的实时数据推送到指定 URL。
- Webhook 提供直接可操作的信息,无需客户端轮询系统。
- notify URL 可用于通知您爬取任务已完成。
- webhook URL 可将实际爬取的数据或完成的详细元数据直接发送给您。
触发收集后,快照可保留多久?
触发收集后,快照可保留多久?
特定爬虫或域名是否有任何限制?
特定爬虫或域名是否有任何限制?
Facebook
| 贴文(按个人资料 URL) | |
| 评论 | |
| Reels |
Instagram
| 贴文(按关键词) | |
| 贴文(按个人资料 URL) | |
| 评论 | |
| Reels |
Pinterest
| 个人资料 | |
| 贴文(按关键词) | |
| 贴文(按个人资料 URL) |
Reddit
| 贴文(按关键词) | |
| 评论 |
TikTok
TikTok
| 个人资料(按搜索 URL) | |
| 评论 | |
| 贴文(按关键词) | |
| 贴文(按个人资料 URL) |
Quora
Quora
| 贴文 |
Vimeo
Vimeo
| 贴文(按关键词) | |
| 贴文(按 URL) |
X (Twitter)
X (Twitter)
| 贴文 |
YouTube
YouTube
| 个人资料 | |
| 贴文(按关键词) | |
| 贴文(按 URL) | |
| 贴文(按搜索过滤条件) |
TikTok
TikTok
Linkedin
当快照被标记为空时意味着什么?
当快照被标记为空时意味着什么?
- 错误:在数据收集过程中遇到的问题,例如无效输入、系统错误或访问限制。
- 无效页面:无法访问的页面,原因可能包括 404 错误(页面未找到)、内容已移除(例如不可用的产品)或访问受限。
include_errors=true,它将显示快照中的错误信息和无效页面信息。这有助于您诊断并理解快照中的问题。如何停止 Web Scraper 任务?
如何停止 Web Scraper 任务?
您提供哪些域名的爬虫?
您提供哪些域名的爬虫?
我如何使用 Bright Data 通过 API 访问酒店数据?
我如何使用 Bright Data 通过 API 访问酒店数据?
我如何获取所需的数据?
我如何获取所需的数据?
- 选项 1:丰富的预收集数据 – 探索我们的数据集市场
- 选项 2:用于实时数据的新鲜爬虫
我们提供广泛的热门网站预建爬虫,让您快速高效地收集数据。这些爬虫可直接使用,设置简单,非常适合希望快速上手的用户。定制爬虫
如果在预建爬虫列表中找不到目标网站,也没问题\! 我们可以为您创建专属定制爬虫。我们的专家团队将与您合作,设计能够收集精确所需数据的解决方案。自行构建爬虫
对于具备 JavaScript 知识或开发资源的用户,我们还提供使用集成开发环境(IDE)构建爬虫的选项。这让您可以完全控制并灵活地创建符合您独特需求的爬虫。如有疑问或需要帮助,我们的专家团队随时为您提供支持。让我们开始吧\!
我如何从 Google Maps 抓取数据?
我如何从 Google Maps 抓取数据?
- 在控制面板找到“Google Maps 评论”爬虫,选择以 API 请求运行或使用“无代码”选项启动。
- 输入参数(地点页面 URL 以及要检索评论的天数)。
- 配置所需请求参数(如果使用 API)。
- 启动运行并收集数据。
我如何取消正在运行的快照?
我如何取消正在运行的快照?
- API 请求:
-
发送
POST请求至端点: POST /datasets/v3/snapshot/cencel (playground) -
将
{snapshot_id}替换为要取消的快照 ID。
- 控制面板:
- 转到爬虫的 日志 标签。
- 找到正在运行的快照。
- 将鼠标悬停在特定运行上,点击 “X” 进行取消。
当“SearchGPT”处于激活状态时,ChatGPT 爬虫能工作吗?
当“SearchGPT”处于激活状态时,ChatGPT 爬虫能工作吗?
我可以查看爬虫的代码吗?
我可以查看爬虫的代码吗?
对于希望了解爬虫工作原理的用户,Web Scraper IDE 在创建新爬虫时提供多个示例模板。这些示例可作为实用参考,帮助您理解爬虫技术并构建自己的定制解决方案。
我可以在使用 Scrapers 时直接将结果获取到我的本地或软件中吗?
我可以在使用 Scrapers 时直接将结果获取到我的本地或软件中吗?
什么是 Dataset ID,我在哪里可以找到?
什么是 Dataset ID,我在哪里可以找到?
https://api.brightdata.com/datasets/v3/trigger?dataset_id=DATASET_ID_HEREDataset ID 示例:gd_XXXXXXXXXXXXXXXXX例如:
gd_l1viktl72bvl7bjuj0您可以在感兴趣爬虫的 Scrapers 页面中,在 API 请求生成器 标签下找到精确的 Dataset ID,已自动填入 API 请求,方便复制使用。注意:类似 s_XXXXXXXXXXXXXXXXXX 的 ID,例如 s_m7hm4et0141r2rhojq 不是 Dataset ID,而是快照 ID——快照是从单次 Scrapers 请求收集的数据集合。什么是“仅发现”模式?
什么是“仅发现”模式?
是否可以重新运行失败的快照?
是否可以重新运行失败的快照?
如何取回您的原始输入?
如何取回您的原始输入?
UI 中的“同步(实时)”和“异步”有什么区别?
UI 中的“同步(实时)”和“异步”有什么区别?
| UI 标签 | API 端点 | 适用场景 |
|---|---|---|
| 同步(实时)(Synchronous (Real-time)) | POST /datasets/v3/scrape | 需要对 1–20 个 URL 获取即时结果 |
| 异步(Asynchronous) | POST /datasets/v3/trigger | 处理批量 URL、发现任务或大型数据集 |
我在哪里获取快照 ID?
我在哪里获取快照 ID?
/datasets/v3/trigger)、过滤数据集(POST /datasets/filter)或通过数据集订阅时,都会返回快照 ID。您也可以使用 GET /datasets/v3/snapshots 列出您的所有快照。响应中的交付任务 ID 用来做什么?
响应中的交付任务 ID 用来做什么?
id 是交付任务 ID。使用它调用 GET /datasets/v3/delivery/{delivery_id} 来跟踪交付进度。轮询直到状态为 “done”。快照需要处于特定状态吗?
快照需要处于特定状态吗?
ready 状态。在调用 deliver 之前,使用 GET /datasets/snapshots/{id} 进行检查。可能的状态:scheduled、building、ready、failed。我可以将同一个快照交付到多个目的地吗?
我可以将同一个快照交付到多个目的地吗?
支持哪些文件格式?
支持哪些文件格式?
json、jsonl 和 csv。如何将大型快照拆分为较小的文件?
如何将大型快照拆分为较小的文件?
batch_size 参数设置每个文件的记录数。每个文件(批次)必须低于 5GB 硬性上限。用 5GB 除以您的平均记录大小来估算 batch_size,然后从较低的值开始,并根据实际获得的文件大小进行调整。例如,如果您的平均记录约为 5KB,则 batch_size 为 1,000,000 时文件恰好接近 5GB 上限。建议从 500,000 条记录(约 2.5GB)开始,以确保安全低于上限,然后根据收到的文件大小调高或调低 batch_size。为什么我的请求返回 400 错误?
为什么我的请求返回 400 错误?
batch_size 生成的文件超过 5GB。例如,如果您的平均记录大小约为 5KB,则 batch_size 为 1,000,000 会生成约 5GB 的文件,可能超出限制。请调低 batch_size(例如调至 100,000)后重试。我可以压缩输出吗?
我可以压缩输出吗?
compress: true 即可接收 gzip 压缩的文件。每个批次的最大文件大小是多少?
每个批次的最大文件大小是多少?
batch_size 控制每个文件包含的记录数,确保每个文件都低于此阈值。