前置条件
- 一个 Bright Data 账户(注册 → 2 分钟)
- 一个有效的 API Key(如何获取 API Key)
选择目标网站
- 访问 Scraper Library
- 浏览列表并点击所需网站。
- 找不到?查看 Custom Scrapers 或 Web Scraper IDE 产品,获取定制化解决方案!
选择 Scraper 端点
在网站页面中,您会看到多个 Scraper 端点,例如: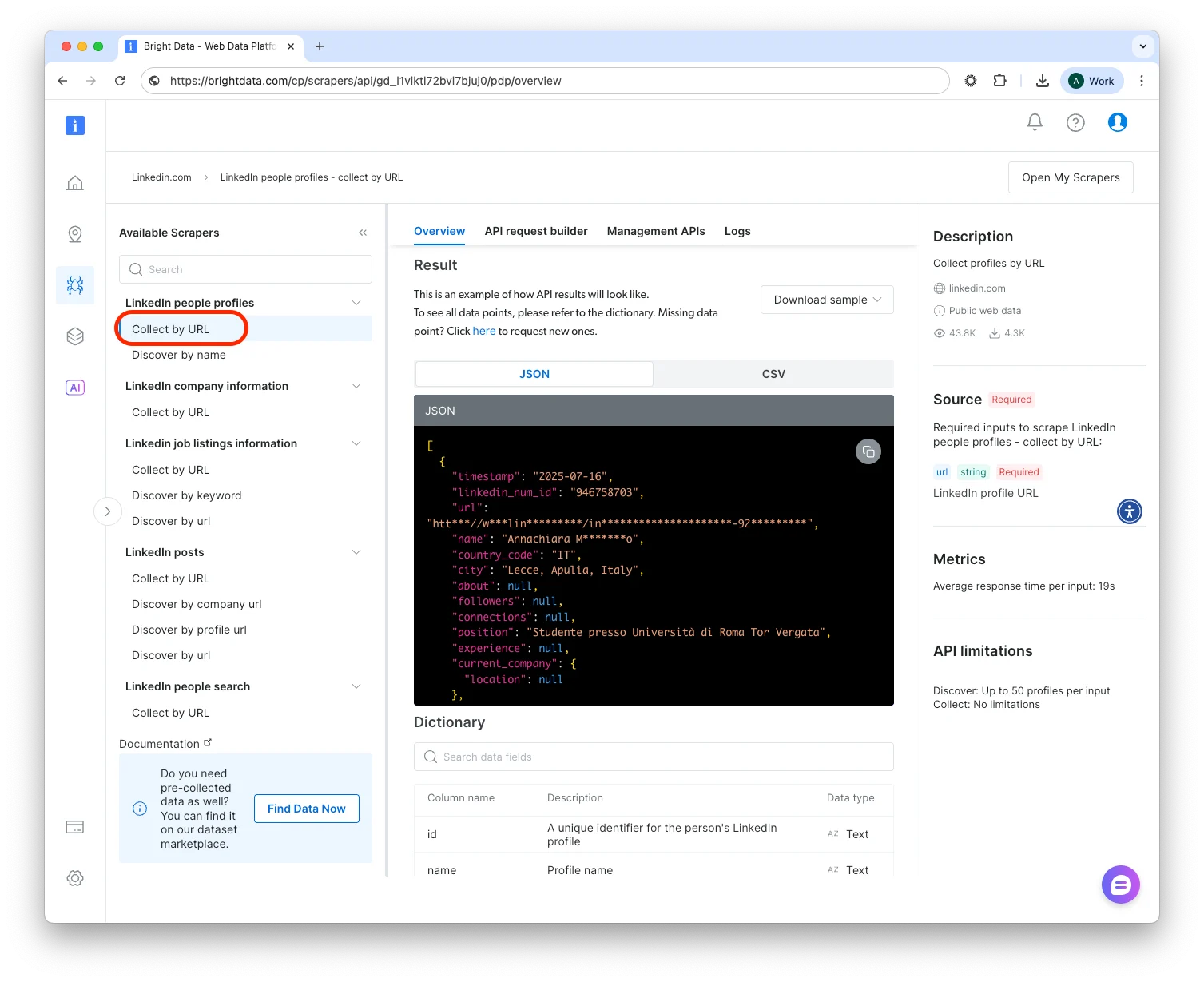
- LinkedIn
- Profile by URL – 提供个人资料 URL,获取公开数据字段。
- Profiles by Keyword – 提供搜索词,获取匹配的个人资料 URL(可选完整数据)。
- Company Jobs – 收集公司页面的职位发布信息。
- Amazon
- 按 ASIN 获取产品、搜索结果、评论、“常一起购买”等。
构建请求
中央面板现在显示表单,从上到下依次填写:A. 输入
- “单个输入”: 直接在文本框粘贴 URL/关键字。
- “批量 CSV”: 上传符合 Scraper 输入参数的 CSV 文件。
- 输出模式 – 勾选仅需要的数据字段(节省带宽和存储)。
- 外部存储 – 填写 S3 / GCS / Azure 等凭据,结果文件将自动存储到指定位置。
- Webhook URL – 作业完成后,我们会 POST JSON 到您的端点,非常适合实时数据管道。
复制代码
- 语言选择器 – 使用代码块下拉选择偏好的编程语言。
- 代码片段已包含:端点 URL、API key 头、payload JSON(输入 + 选项)。
- 将其粘贴到终端 / IDE / serverless 函数中运行。
监控与获取结果
- Scraper 页面 → Logs 标签页
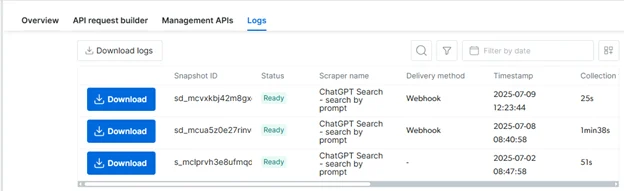
- 实时状态(运行中、准备好、失败)。
- 一键下载 JSON/CSV 等文件。
- Webhook(如已设置)
- 您的服务器会接收到
{snapshot_id, status, result_url}payload。
- 您的服务器会接收到
- 外部存储
- 结果文件会出现在您配置的存储桶路径中。
- 快照管理 API
- 使用这些端点监控快照进度。