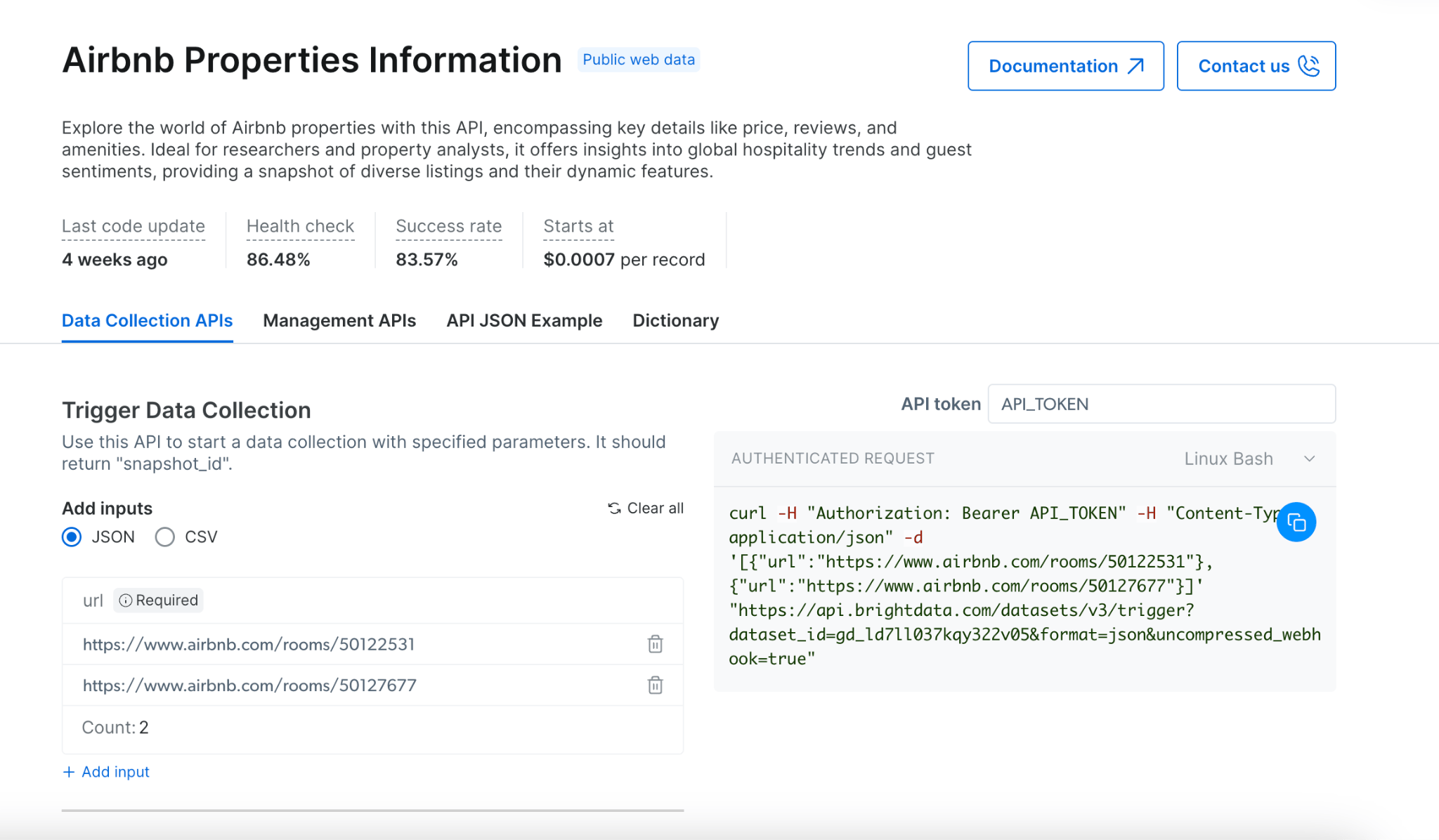
Use Bright Data’s Scrapers Library to extract structured data from 700+ pre-built scrapers via synchronous or asynchronous API calls.
The Scrapers lets you extract data from websites programmatically. It offers both synchronous and asynchronous scraping methods for different use cases, from quick data retrieval to complex, large-scale extraction jobs.The API handles real-time processing for single URL inputs, and batch processing for 2 or more inputs, accommodating various scraping requirements.
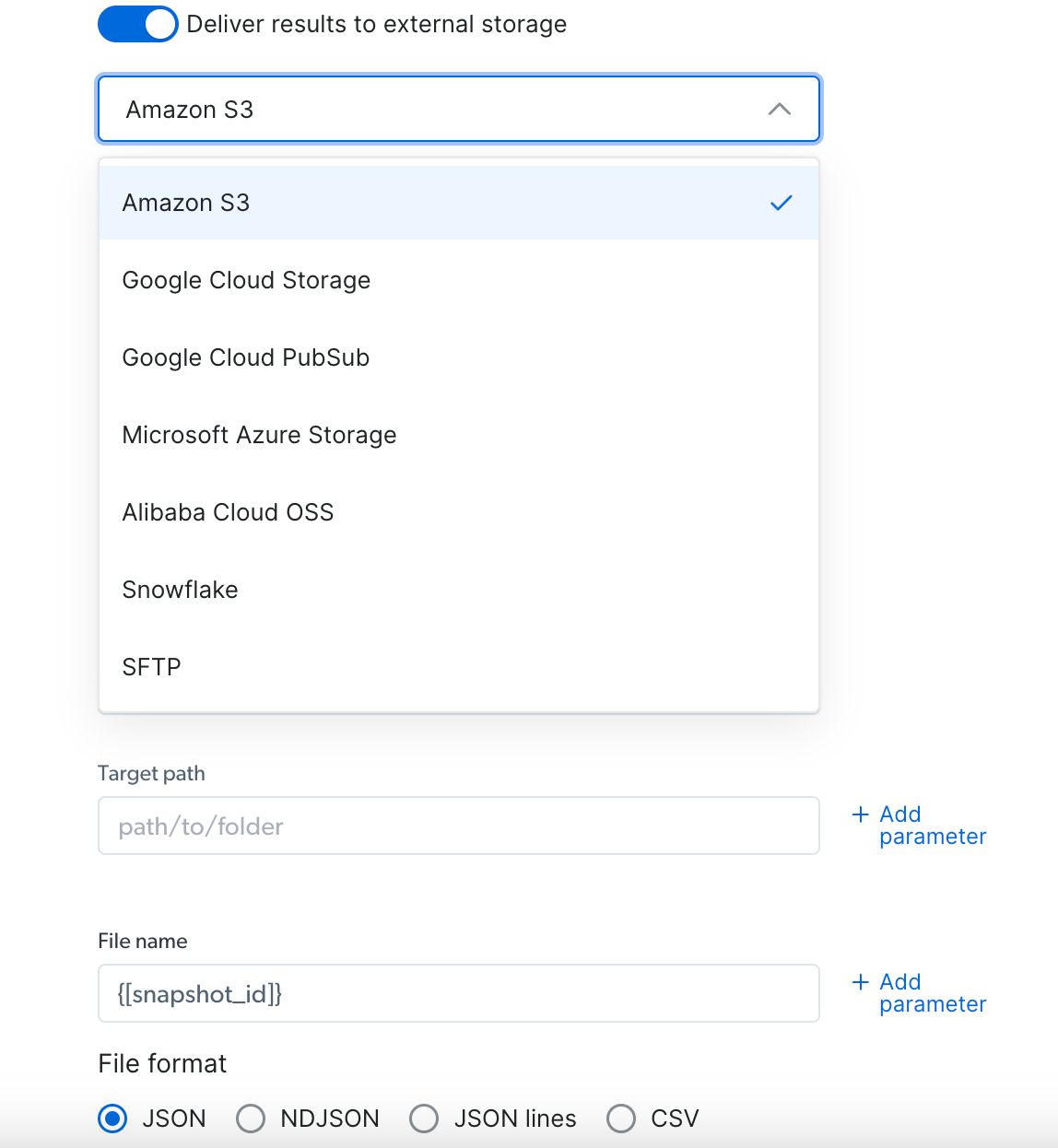
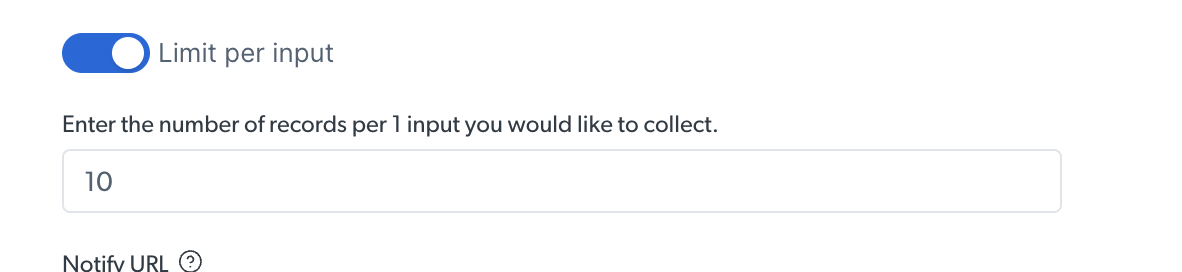
Asynchronous scraping initiates a job that runs in the background, allowing you to handle larger and more complex scraping tasks in batch mode. Batch mode allows up to 100 concurrent requests, and each batch can process up to 1GB of inputs file size, making it ideal for high-volume data collection projects.Discovery tasks (finding related products, scraping multiple pages) require the asynchronous scraping (/trigger) due to their need to navigate and extract data across multiple web pages.
Check your snapshot history with this API. It returns a list of all available snapshots, including the snapshot ID, creation date, and status. (link to endpoint playground)
If you are confused by receiving a snapshot_id, it means an asynchronous call was made. Consider using the synchronous /scrape endpoint for simpler, immediate tasks.
Check your data collection status with this API. It should return “collecting” while gathering data, “digesting” when processing, and “ready” when available. (link to endpoint playground)
Cancel a running collection, stop your data collection before finishing with this API. It should return “ok” while managing to stop the collection. (link to endpoint playground)
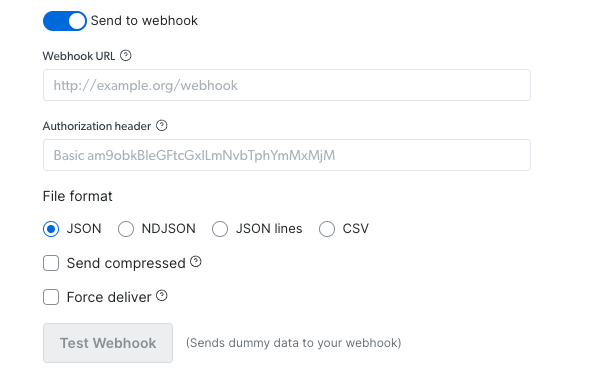
Check your delivery status with this API. It should return “done” while the delivery was completed, “canceled” when the delivery was canceled, and “Failed” when the delivery was not completed. (link to endpoint playground)
To ensure stable performance and fair usage, the Scrapers enforces rate limits based on the type of request: single input or batch input. Exceeding these limits will result in a 429 error response.