前提条件
- 一个已在 Bright Data Scraper Studio IDE 中保存到生产环境的爬虫
- 通过 API 触发或 API 交付时所需的 API key(创建一个)
如何把爬虫保存到生产环境?
在 Bright Data Scraper Studio IDE 中编辑代码时,系统会自动将您的工作保存为开发草稿。要让爬虫能在 IDE 之外运行,请点击 IDE 右上角的 Save to Production(保存到生产环境)。所有生产爬虫会出现在控制面板的 My Scrapers(我的爬虫)下,非活动爬虫以淡化状态显示。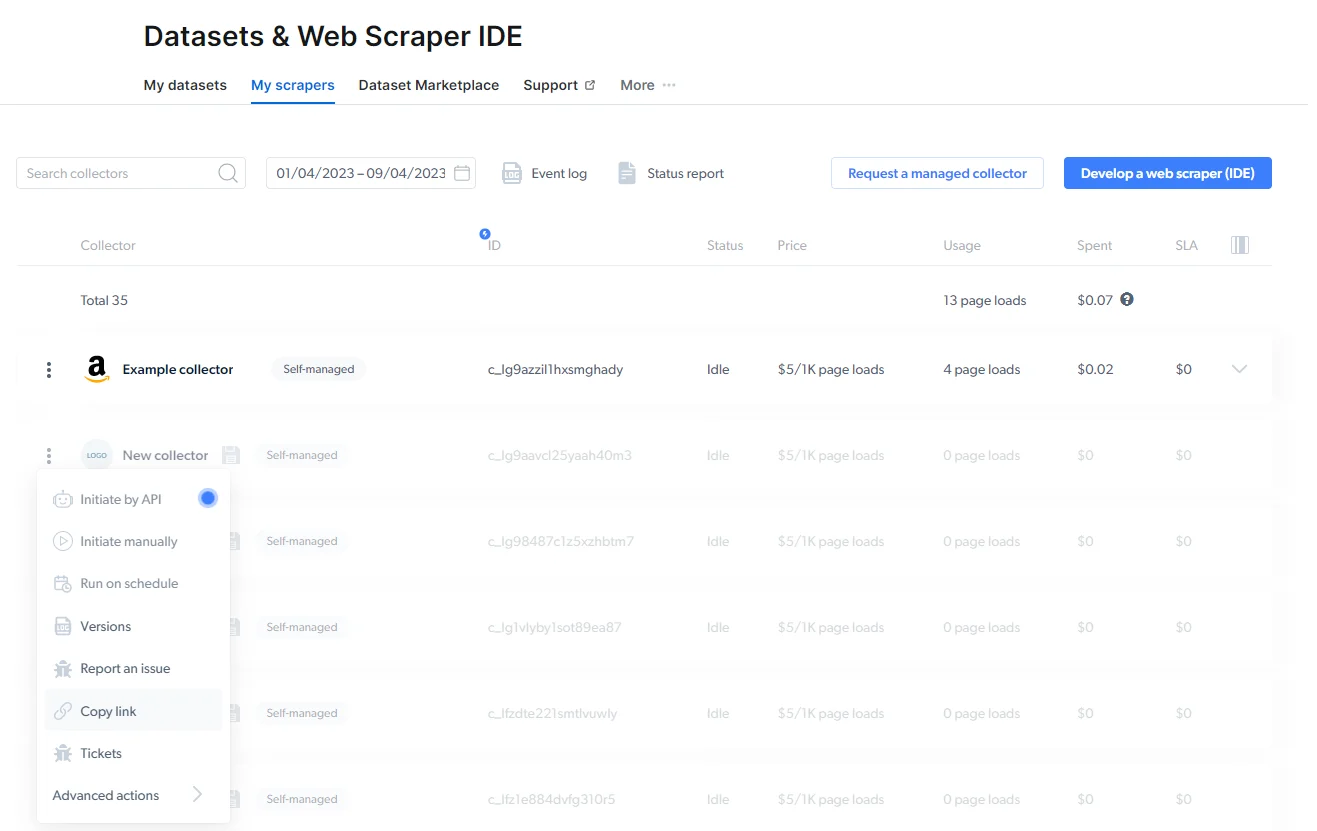
如何触发爬虫运行?
Bright Data Scraper Studio 支持三种启动采集的方式。- 通过 API 启动
- 手动启动
- 按计划运行
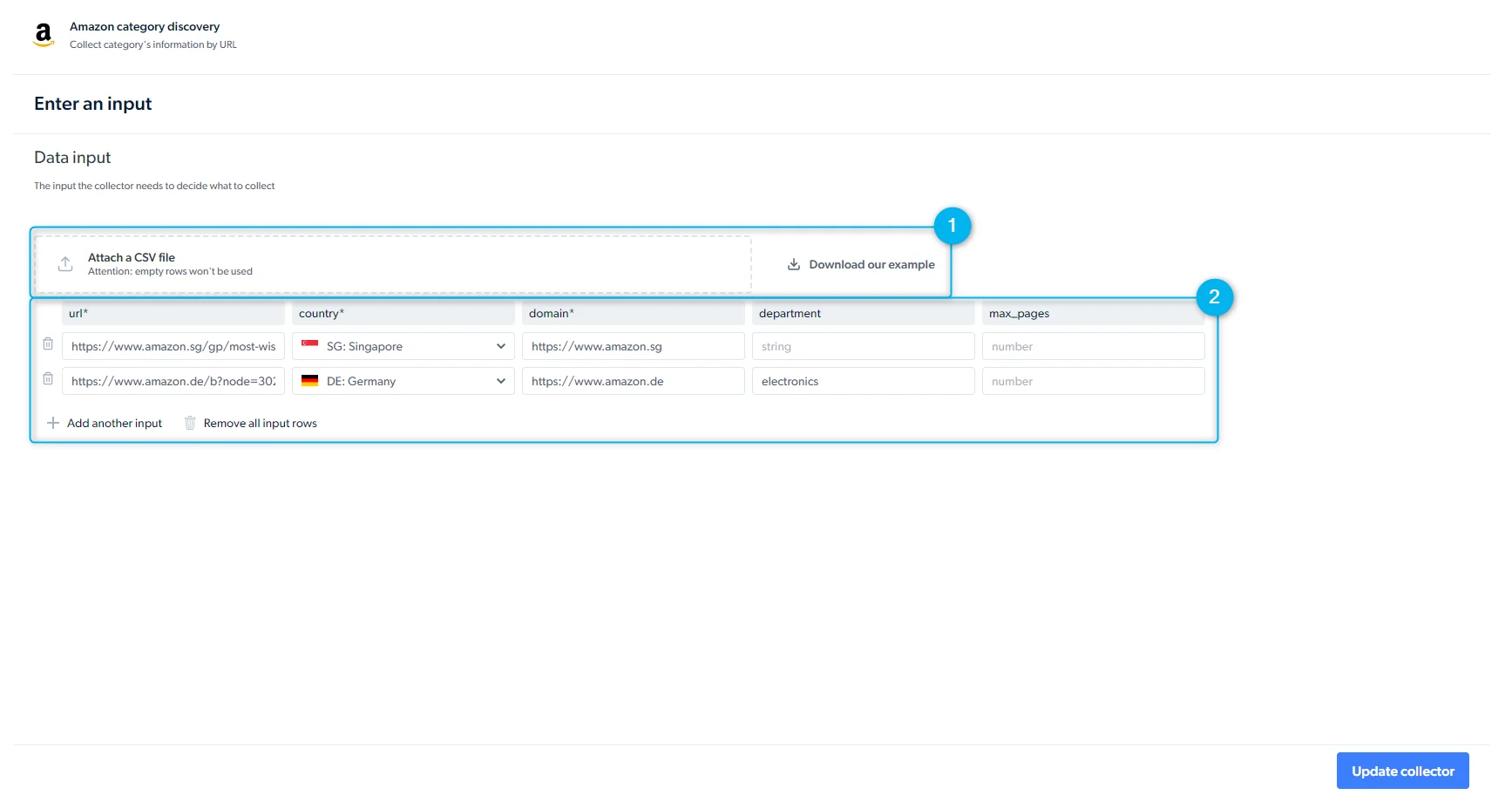
无需打开控制面板,通过 REST API 启动采集。认证、请求格式与响应 schema 请参见 API 入门指南。在发送请求前,请先创建 API key。前往 仪表盘 > 账户设置 > API key。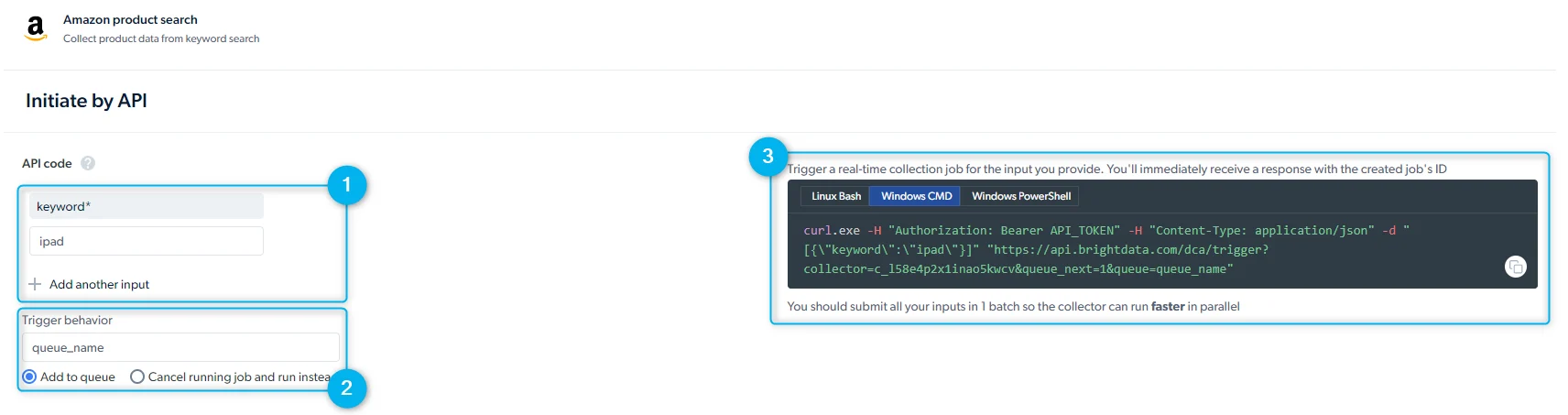
- Inputs(输入): 手动或通过 API 请求体提供输入值
- Trigger behavior(触发行为): 将多个请求加入队列以并行或顺序运行;排队任务按提交顺序执行
- API 请求预览: Bright Data 会为您生成一条可直接运行的
curl命令。请为curl选择 Linux Bash 视图。响应中包含一个collection_id,稍后可用它拉取数据。
当交付方式设置为 API download(API 下载)时,必须调用 “Receive data” API 端点才能获取结果。Webhook 与云存储目的地会自动推送数据。
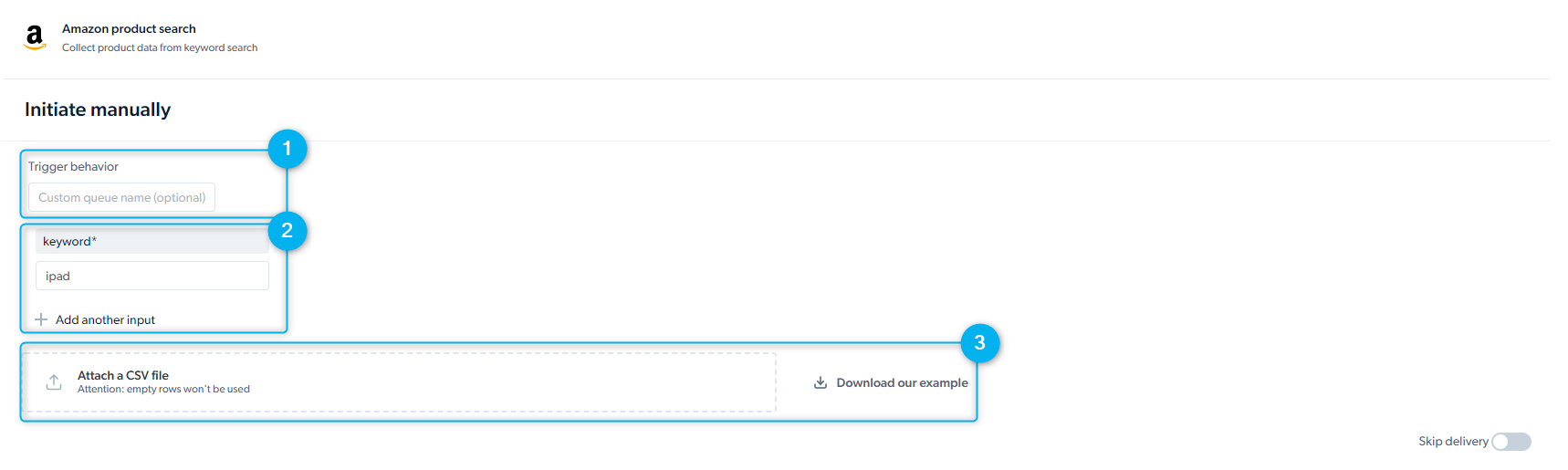
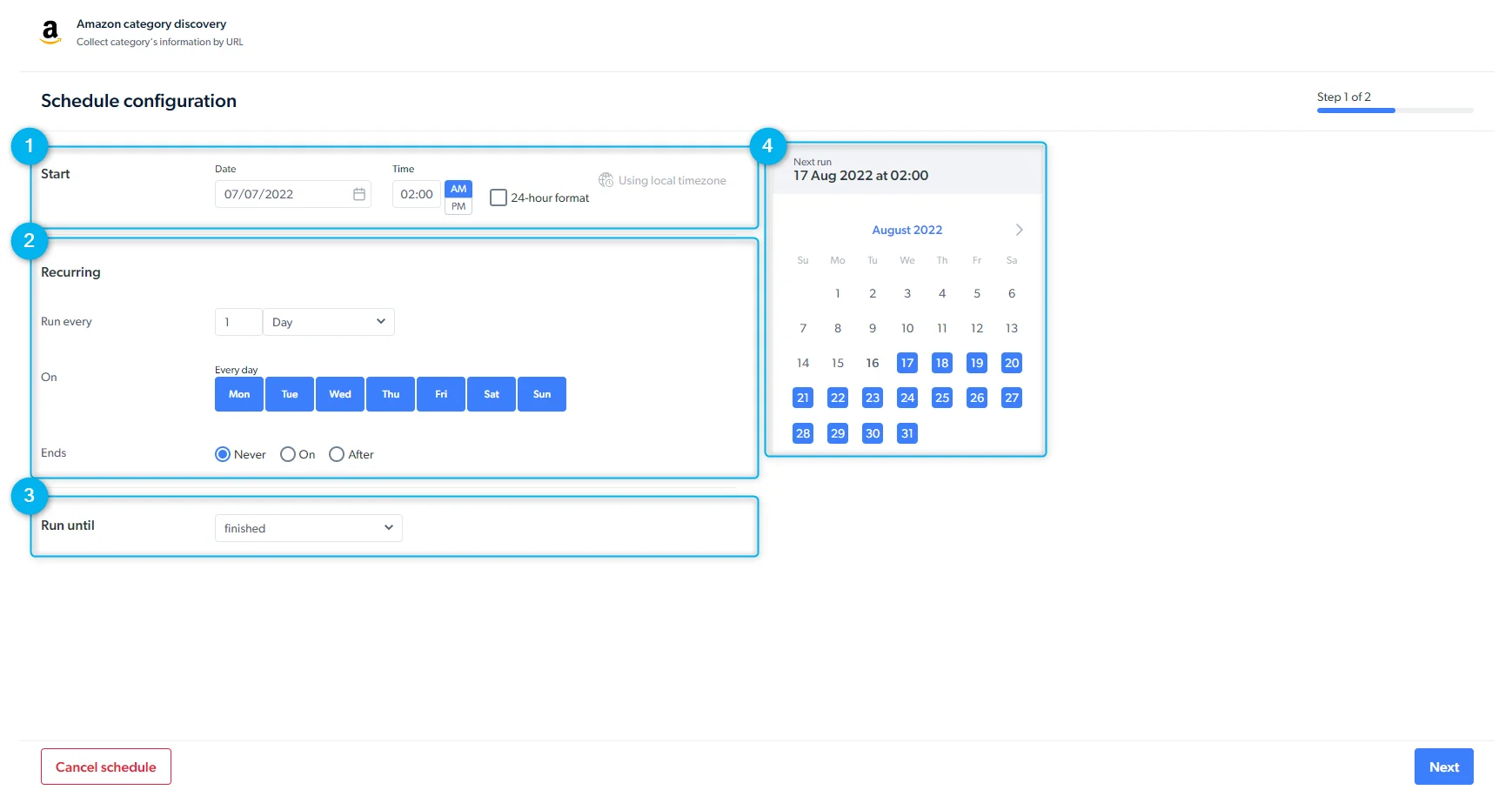
速率限制与并发限制是多少?
Bright Data Scraper Studio 按爬虫强制执行并发限制,依据请求是批量还是实时。| 采集类型 | 并发限制 |
|---|---|
| Batch(批量) | 每个爬虫最多 1,000 个并发请求 |
| Real-time(实时) | 无限制 |
Maximum limit of 1000 jobs per scraper has been exceeded. Please reduce the number of parallel jobs.
批量 vs 实时采集
Bright Data Scraper Studio 提供两种采集方法,分别针对不同使用场景做了优化。| Batch 批量采集 | Real-time 实时采集 | |
|---|---|---|
| 输入规模 | 每个任务多条输入(URL 或关键词列表) | 每个请求一条输入 |
| 响应时机 | 任务全部完成后返回结果 | 实时返回响应 |
| 保留期 | 16 天 | 7 天 |
| 并发限制 | 1,000 个并发任务 | 无 |
| 适用场景 | 构建数据集且可等待 | 在一次实时请求内得到结果 |
如何配置交付?
打开 My Scrapers,点击爬虫所在行,选择 Delivery preferences(交付偏好)以设置 Bright Data Scraper Studio 投递结果的目的地与方式。什么时候接收数据?
什么时候接收数据?
- Batch(批量): 整个任务完成后获取结果;适合大数据集
- Split batch(分批): 准备就绪的部分结果以小批次先行交付
- Real-time(实时): 获取单次请求的快速响应
- Skip retries(跳过重试): 出错时不重试(以完整性换取速度)
支持哪些文件格式?
支持哪些文件格式?
- JSON
- NDJSON
- CSV
- XLSX
- Parquet
支持哪些交付目的地?
支持哪些交付目的地?
- 电子邮件
- API 下载(通过 REST API 拉取)
- Webhook(通过 HTTPS POST 推送)
- 云存储:Amazon S3、Google Cloud Storage、Azure Blob Storage、Alibaba Cloud OSS
- SFTP / FTP
媒体文件无法通过电子邮件或 API 下载交付。采集图片、视频或其他二进制内容时请使用云存储、SFTP 或 webhook。
如何控制批量输出的内容?
如何控制批量输出的内容?
- 结果与错误分别输出到两个文件
- 结果与错误合并到一个文件
- 仅成功的结果
- 仅错误
可启用哪些通知?
可启用哪些通知?
- 采集完成时通知
- 触达成功率阈值时通知
- 出现错误时通知
如何配置输出 schema?
输出 schema 定义您所采集数据的结构:字段名、数据类型、默认值,以及您希望 Bright Data Scraper Studio 附加的任何额外元数据(时间戳、截图、WARC 快照)。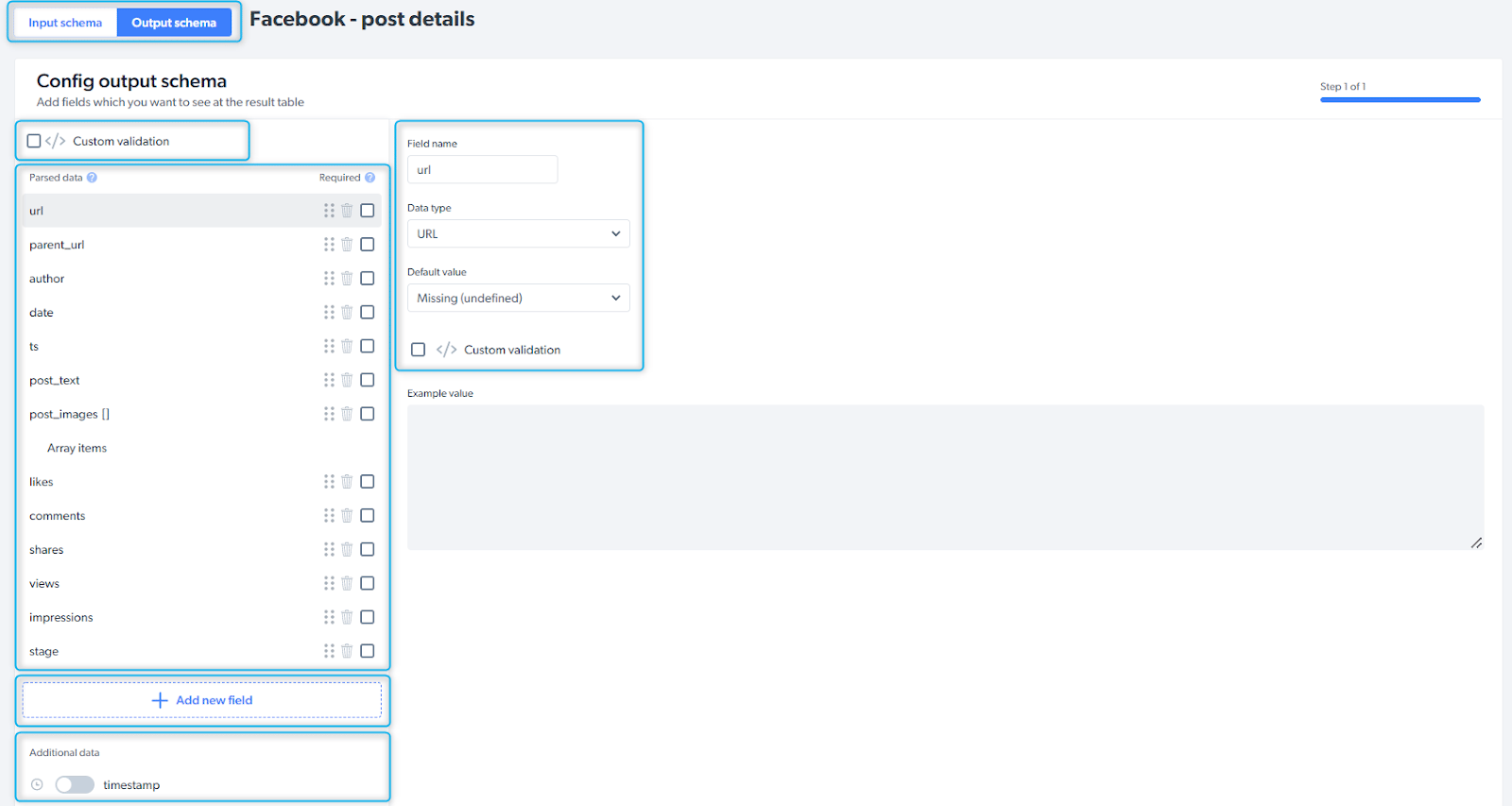
| 控件 | 说明 |
|---|---|
| Input / Output schema | 在输入与输出两种 schema 视图之间切换 |
| Custom validation | 定义对每条采集记录运行的校验规则 |
| Parsed data | 爬虫解析器代码输出的原始字段 |
| Add new field | 按名称与类型新增字段 |
| Additional data | 可选元数据:时间戳、截图、WARC 快照等 |
相关内容
Scraper Studio 规格说明
基础设施限制、计费与数据保留
WARC 快照
在采集数据的同时归档原始 HTTP 响应