Expand to get your Bright Data Proxy Access Information
Expand to get your Bright Data Proxy Access Information
Your proxy access information
Bright Data proxies are grouped in “Proxy zones”. Each zone holds the configuration for the proxies it holds.To get access to the proxy zone:- Login to Bright Data control panel
- Select the proxy zone or setup a new one
- Click on the new zone name, and select the Overview tab.
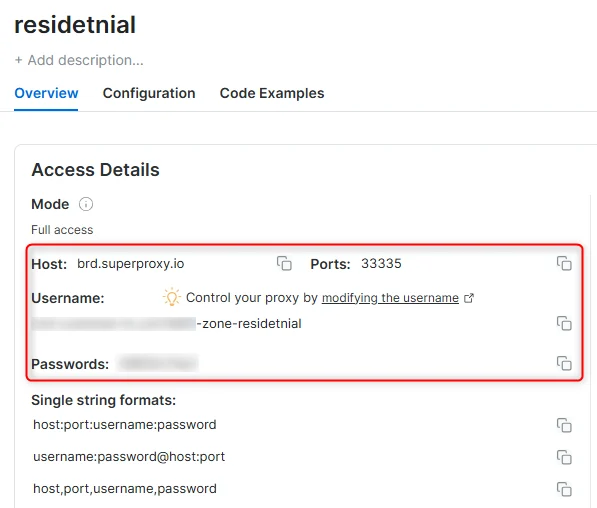
- In the overview tab, under Access details you can find the proxy access details, and copy them to clipboard on click.
- You will need: Proxy Host, Proxy Port, Proxy Zone username and Proxy Zone password.
- Click on the copy icons to copy the text to your clipboard and paste in your tool’s proxy configuration.
Access Details Section Example
Residential proxy access
To access Bright Data’s Residential Proxies you will need to either get verified by our compliance team, or install a certificate. Read more…Targeting search engines?
If you target a search engine like google, bing or yandex, you need a special Search Engine Results Page (SERP) proxy API. Use Bright Data SERP API to target search engines. Click here to read more about Bright Data SERP proxy API.Correct setup of proxy test to avoid “PROXY ERROR”
In many tools you will see a “test proxy” function, which performs a conncectivity test to your proxy, and some add a geolocation test as well, to identify the location of the proxy. To correctly test your proxy you should target those search queries to:https://geo.brdtest.com/welcome.txt .Some tools use popular search engines (like google.com) as a default test target. Bright Data will block those requests and you tool will show proxy error although your proxy is perfectly fine.If your proxy test fails, this is probably the reason. Make sure that your test domain is not a search engine (this is done in the tool configuration, and not controlled by Bright Data).What is BeautifulSoup?
BeautifulSoup is a Python library that simplifies the process of extracting and organizing data from HTML and XML documents. Combined with Bright Data proxies, it enables you to scrape data securely and anonymously while reducing the risk of detection and blocking.How to Integrate Bright Data with BeautifulSoup
Step 0. Prerequisites Before you start:- Download the latest Python version from python.org.
-
Install BeautifulSoup and the
requestslibrary:
-
Log in to your Bright Data account and retrieve your proxy credentials:
-
Host:
http://brd.superproxy.io/ - Port: 33335
-
Username: Your Bright Data username. Modify it for geo-specific proxies if needed (e.g.,
your-username-country-US). - Password: Your Bright Data proxy zone password.
-
Host:
- Define your proxy details in your script: