展开以获取您的 Bright Data 代理访问信息
展开以获取您的 Bright Data 代理访问信息
您的代理访问信息
Bright Data 代理按“代理区域”(Proxy zones)进行分组。每个区域包含其对应的代理配置。 要获取代理区域的访问权限:- 登录 Bright Data 控制面板
- 选择现有代理区域或新建一个代理区域
- 点击新的区域名称,并选择 概览(Overview) 选项卡
- 在概览选项卡中,找到 访问详情(Access details),并单击复制图标将代理访问信息复制到剪贴板
- 您需要以下信息:代理主机(Proxy Host)、代理端口(Proxy Port)、代理区域用户名(Proxy Zone username)和代理区域密码(Proxy Zone password)
- 点击复制图标,将文本复制到剪贴板,并粘贴到您的工具的代理配置中
访问详情示例
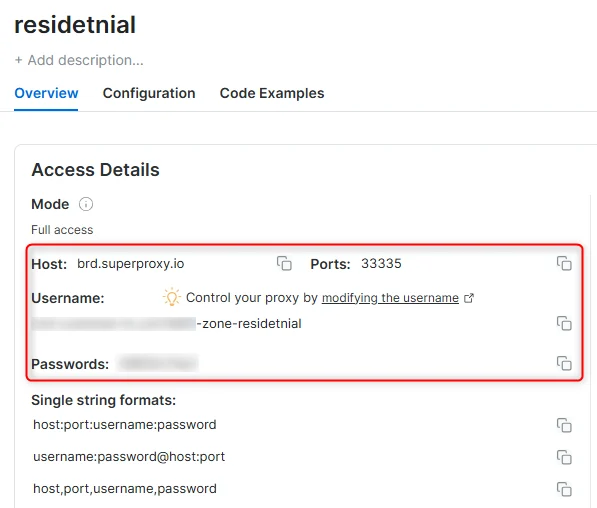
住宅代理访问
要使用 Bright Data 的 住宅代理(Residential Proxies),您必须是经过 KYC 验证的企业账户。请与 Bright Data 合规团队完成 KYC 验证;不存在自动或无需 KYC 的访问方式。尚未完成 KYC 时,请使用 ISP 或数据中心代理。了解更多…目标是搜索引擎?
如果您的目标是 Google、Bing 或 Yandex 等搜索引擎,则需要使用专门的搜索引擎结果页(SERP)代理 API。请使用 Bright Data SERP API 来访问搜索引擎。点击此处了解 Bright Data SERP 代理 API。
避免工具中的 PROXY ERROR
一些工具会使用搜索引擎作为代理测试目标:如果您的代理测试失败,这可能就是原因。请确保您的测试目标域名不是搜索引擎(此设置在工具配置中,而非 Bright Data 代理的控制范围内)。什么是 BeautifulSoup?
BeautifulSoup 是一个 Python 库,它简化了从 HTML 和 XML 文档中提取和整理数据的过程。结合 Bright Data 代理,它可以帮助您安全、匿名地爬取数据,并降低被检测和封锁的风险。如何将 Bright Data 与 BeautifulSoup 集成
步骤 0. 先决条件 开始之前:- 从 python.org 下载最新的 Python 版本。
-
安装 BeautifulSoup 和
requests库:
-
登录您的 Bright Data 账户 并获取代理凭据:
-
主机:
http://brd.superproxy.io/ - 端口: 33335
-
用户名: 您的 Bright Data 用户名。如果需要使用特定国家的代理,请修改用户名(例如:
your-username-country-US)。 - 密码: 您的 Bright Data 代理区域密码。
-
主机:
- 在您的脚本中定义代理详细信息: