展开以获取您的 Bright Data 代理访问信息
展开以获取您的 Bright Data 代理访问信息
您的代理访问信息
Bright Data 代理按“代理区域”(Proxy zones)进行分组。每个区域包含其对应的代理配置。 要获取代理区域的访问权限:- 登录 Bright Data 控制面板
- 选择现有代理区域或新建一个代理区域
- 点击新的区域名称,并选择 概览(Overview) 选项卡
- 在概览选项卡中,找到 访问详情(Access details),并单击复制图标将代理访问信息复制到剪贴板
- 您需要以下信息:代理主机(Proxy Host)、代理端口(Proxy Port)、代理区域用户名(Proxy Zone username)和代理区域密码(Proxy Zone password)
- 点击复制图标,将文本复制到剪贴板,并粘贴到您的工具的代理配置中
访问详情示例
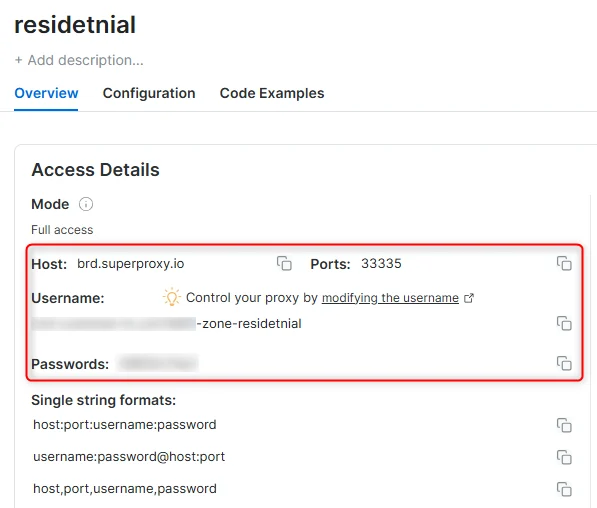
住宅代理访问
要使用 Bright Data 的 住宅代理(Residential Proxies),您必须是经过 KYC 验证的企业账户。请与 Bright Data 合规团队完成 KYC 验证;不存在自动或无需 KYC 的访问方式。尚未完成 KYC 时,请使用 ISP 或数据中心代理。了解更多…目标是搜索引擎?
如果您的目标是 Google、Bing 或 Yandex 等搜索引擎,则需要使用专门的搜索引擎结果页(SERP)代理 API。请使用 Bright Data SERP API 来访问搜索引擎。点击此处了解 Bright Data SERP 代理 API。
避免工具中的 PROXY ERROR
一些工具会使用搜索引擎作为代理测试目标:如果您的代理测试失败,这可能就是原因。请确保您的测试目标域名不是搜索引擎(此设置在工具配置中,而非 Bright Data 代理的控制范围内)。什么是 Scrapy?
Scrapy 是一个强大的 Python 框架,用于网页抓取和数据提取。它以速度和可扩展性为设计目标,帮助开发者高效地爬取网站并收集结构化数据。通过将 Bright Data 代理集成到 Scrapy 中,您可以使用安全、匿名且支持地理定位的连接来增强抓取任务。为什么在 Scrapy 中使用 Bright Data?
- 隐私保护:掩盖您的真实 IP,在抓取时保持匿名。
- 地理定位数据访问:使用 Bright Data 的国家特定代理,从不同地区获取数据。
- 可靠性提升:通过分配请求到 Bright Data 代理,降低被检测或封禁的风险。
Scrapy 项目设置指南
步骤 0:前提条件
开始之前,请确保您具备以下条件:-
已安装 Python:
- 从 python.org 下载并安装最新版。
-
已安装 Scrapy:在终端中运行:
-
Bright Data 代理凭据:
- 登录 Bright Data 仪表板 获取代理信息(Host、Port、Username 和 Password)。
- 对于地区特定代理,请使用格式
your-username-country-XX修改用户名,例如your-username-country-US。
步骤 1:创建或打开 Scrapy 项目
-
如果没有 Scrapy 项目,可运行:
将 “myproject” 替换为项目名称,例如 “brightdata_test” 或 “web_scraper”。
-
进入项目目录:
步骤 2:生成 Spider
-
使用 Scrapy 命令创建一个 spider:
例如,要抓取 httpbin.org/ip:
-
生成的 spider 模板位于
spiders/目录,例如:
步骤 3:配置 Bright Data 代理
-
打开 spider 文件 (
spiders/BrightDataExample.py) 并修改为以下示例: -
将
[USERNAME]、[PASSWORD]、[HOST]和[PORT]替换为 Bright Data 凭据。若需指定国家代理,请修改用户名,例如your-username-country-US。
步骤 4:运行 Scrapy Spider
-
在终端进入项目目录:
-
运行 spider:
-
若需保存输出至文件:
步骤 5:验证输出
-
若配置正确,spider 会显示所使用 Bright Data 代理的 IP,例如:
- 打开 output.json 文件(若使用 -o 参数)查看抓取数据。