How to Get WARC File Output
Overview Web Scraper IDE now supports returning the full HTTP response in WARC (Web ARChive) format. This feature allows you to archive the exact content and metadata of a web page as it was received during scraping. What is a WARC File? WARC is a standardized file format used to store web crawls and HTTP interactions. It is commonly used in digital preservation, research, and compliance scenarios. How to Enable WARC Output WARC files are available only for browser workers To include WARC files in your scraping results:- Open your Web-Scraper IDE configuration.
- In the Output Schema, under ‘additional_data’ field, click the eye icon next to warc_snapshot.
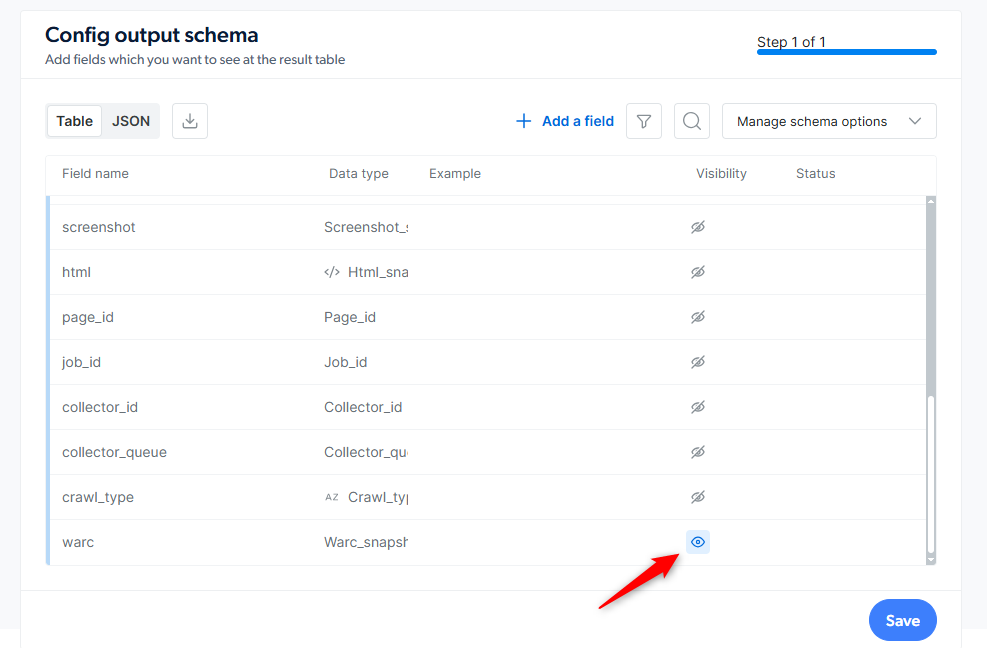
- Save and run a job
- Once the job completes, the WARC file(s) will be delivered to you according to the scraper’s delivery settings.
- WARC capture is limited to browser-side requests only. This includes all network activity initiated by the browser during page load (e.g., HTML, CSS, JS, images, XHR requests).
- Use the wait_network_idle() function in your scraping workflow to allow the browser to finish loading all resources before the WARC is finalized. This helps maximize the completeness of the captured data.