Expand to get your Bright Data Proxy Access Information
Expand to get your Bright Data Proxy Access Information
Your proxy access information
Bright Data proxies are grouped in “Proxy zones”. Each zone holds the configuration for the proxies it holds.To get access to the proxy zone:- Login to Bright Data control panel
- Select the proxy zone or setup a new one
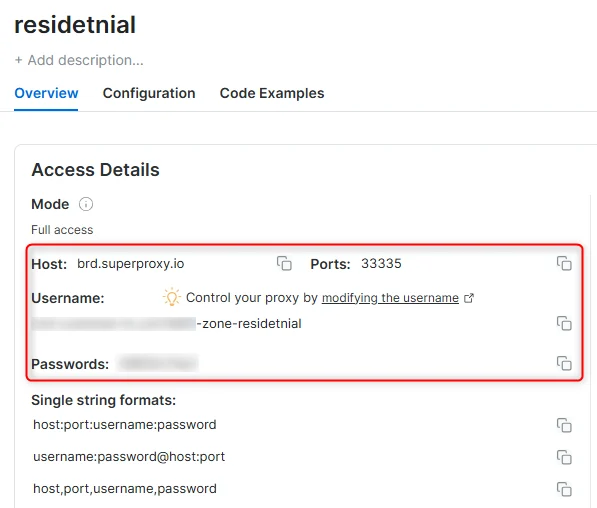
- Click on the new zone name, and select the Overview tab.
- In the overview tab, under Access details you can find the proxy access details, and copy them to clipboard on click.
- You will need: Proxy Host, Proxy Port, Proxy Zone username and Proxy Zone password.
- Click on the copy icons to copy the text to your clipboard and paste in your tool’s proxy configuration.
Access Details Section Example
Residential proxy access
To access Bright Data’s Residential Proxies you must be a KYC-verified business account. Complete KYC verification with the Bright Data compliance team; there is no automatic or no-KYC path. Without KYC, use ISP or Datacenter proxies. Read more…Targeting search engines?
If you target a search engine like google, bing or yandex, you need a special Search Engine Results Page (SERP) proxy API. Use Bright Data SERP API to target search engines. Click here to read more about Bright Data SERP proxy API.Correct setup of proxy test to avoid “PROXY ERROR”
In many tools you will see a “test proxy” function, which performs a conncectivity test to your proxy, and some add a geolocation test as well, to identify the location of the proxy. To correctly test your proxy you should target those search queries to:https://geo.brdtest.com/welcome.txt .Some tools use popular search engines (like google.com) as a default test target. Bright Data will block those requests and you tool will show proxy error although your proxy is perfectly fine.If your proxy test fails, this is probably the reason. Make sure that your test domain is not a search engine (this is done in the tool configuration, and not controlled by Bright Data).What is Scrapy?
Scrapy is a powerful Python-based framework for web scraping and data extraction. Designed for speed and scalability, Scrapy helps developers crawl websites and collect structured data efficiently. By integrating Bright Data proxies into Scrapy, you can enhance your scraping tasks with secure, anonymous, and geo-targeted connections.Why Use Bright Data with Scrapy?
- Enhanced Privacy: Mask your IP to stay anonymous while scraping.
- Geo-Targeted Data Access: Use Bright Data’s country-specific proxies to gather data from different regions.
- Improved Reliability: Reduce the risk of detection or being blocked by distributing requests across Bright Data proxies.
How to Set Up and Start a Scrapy Project
Step 0. Prerequisites Before you begin, ensure you have:-
Python Installed:
- Download and install the latest version from python.org.
-
Scrapy Installed: Run the following command in your terminal to install Scrapy:
-
Bright Data Proxy Credentials:
- Log in to your Bright Data dashboard and retrieve your proxy details (Host, Port, Username, and Password).
- For region-specific proxies, modify your username using the format
your-username-country-XX(e.g.,your-username-country-USfor a US proxy).
-
If you don’t have a Scrapy project, create one by running:
Replace “myproject” with a name that reflects the purpose of your project, such as “brightdata_test” or “web_scraper”.
-
Navigate to your project folder:
-
Use Scrapy’s command to create a spider:
For example, to scrape httpbin.org/ip, you can run:
-
This generates a basic spider template located in the
spiders/directory of your project. It looks something like this:
-
Open the generated spider file in a text editor (
spiders/BrightDataExample.py) and update it to include Bright Data proxy settings. Here’s an example: -
Replace [USERNAME], [PASSWORD], [HOST], and [PORT] with your Bright Data credentials. If you need a country-specific proxy, modify the username (e.g.,
your-username-country-US).
-
Navigate to the project directory in your terminal:
-
Run the spider:
-
To save the output to a file, use:
-
If everything is configured correctly, the spider will display the IP address of the Bright Data proxy it’s using. Example output:
- Open the output.json file (if you used the -o flag) to review the scraped data.