What is a Bright Data Web Scraper?
What is a Bright Data Web Scraper?
What is Web Scraper IDE?
What is Web Scraper IDE?
- Build your scraper in minutes
- Debug and diagnose with ease
- Bring to production quickly
- Browser scripting in simple Javascript
What is an “input” when using a Web Scraper?
What is an “input” when using a Web Scraper?
What is an “output” when using a Web Scraper?
What is an “output” when using a Web Scraper?
How many free records are included with my free trial?
How many free records are included with my free trial?
Why did I receive more statistic records than inputs?
Why did I receive more statistic records than inputs?
What are the most frequent data points collected from social media?
What are the most frequent data points collected from social media?
Can I collect data from multiple platforms?
Can I collect data from multiple platforms?
Can I add additional information to my Web Scraper?
Can I add additional information to my Web Scraper?
What is a search scraper?
What is a search scraper?
What is a discovery scraper?
What is a discovery scraper?
Can I change the code in the IDE by myself?
Can I change the code in the IDE by myself?
What are the options to initiate requests?
What are the options to initiate requests?
- Initiate by API - regular request, queue request and replace request.
- Initiate manually.
- Schedule mode
How to start using the Web Scraper?
How to start using the Web Scraper?
What is a queue request?
What is a queue request?
What is a CPM?
What is a CPM?
When building a scraper, what is considered as a billable event?
When building a scraper, what is considered as a billable event?
navigate()request()load_more()- (later) media file download
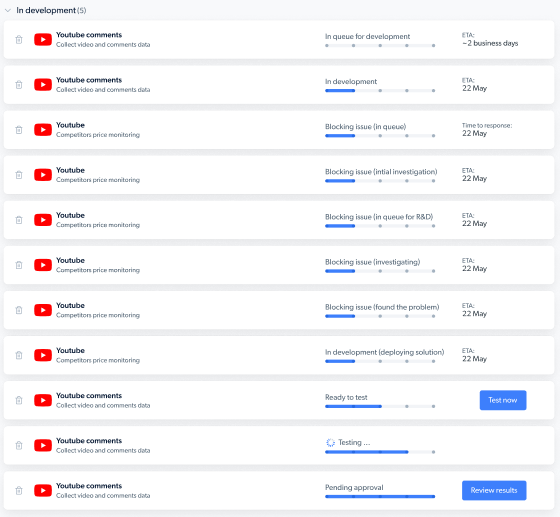
How can I confirm that someone is working on the new Web Scraper I requested?
How can I confirm that someone is working on the new Web Scraper I requested?
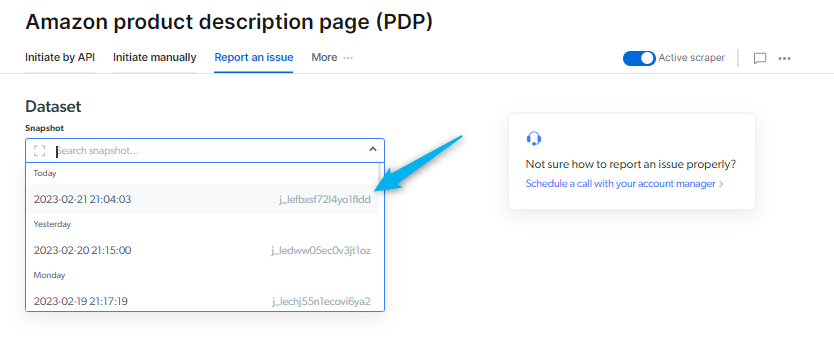
How to report an issue on the Web scraper IDE?
How to report an issue on the Web scraper IDE?
Select a job ID : issued Dataset
Select a type of the issue
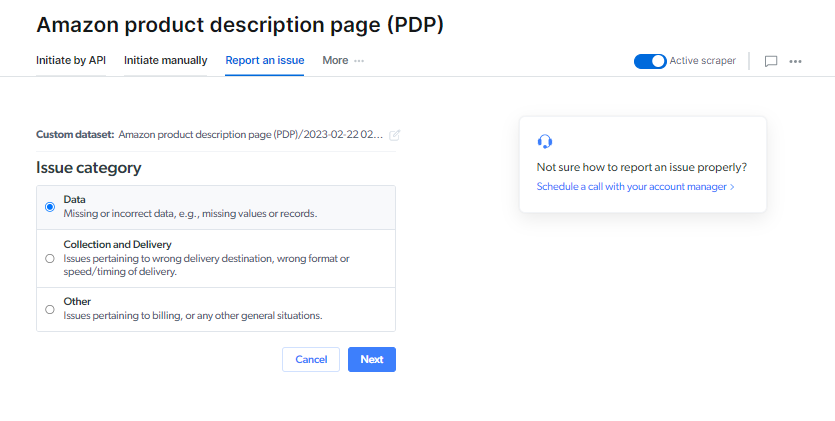
Data
Data
- Missing fields
- Missing records
- Missing values
- Parsing issues: The dataset results are incorrect
Collection and Delivery
Collection and Delivery
- Incomplete delivery: Something went wrong during the delivery
- Scraper is slow: The scraper is collecting results slowly or stuck
Other
Other
- UI issue : UI does not operate correctly
- Product question: General questions regarding using Web Scraper product
- Something else is going wrong
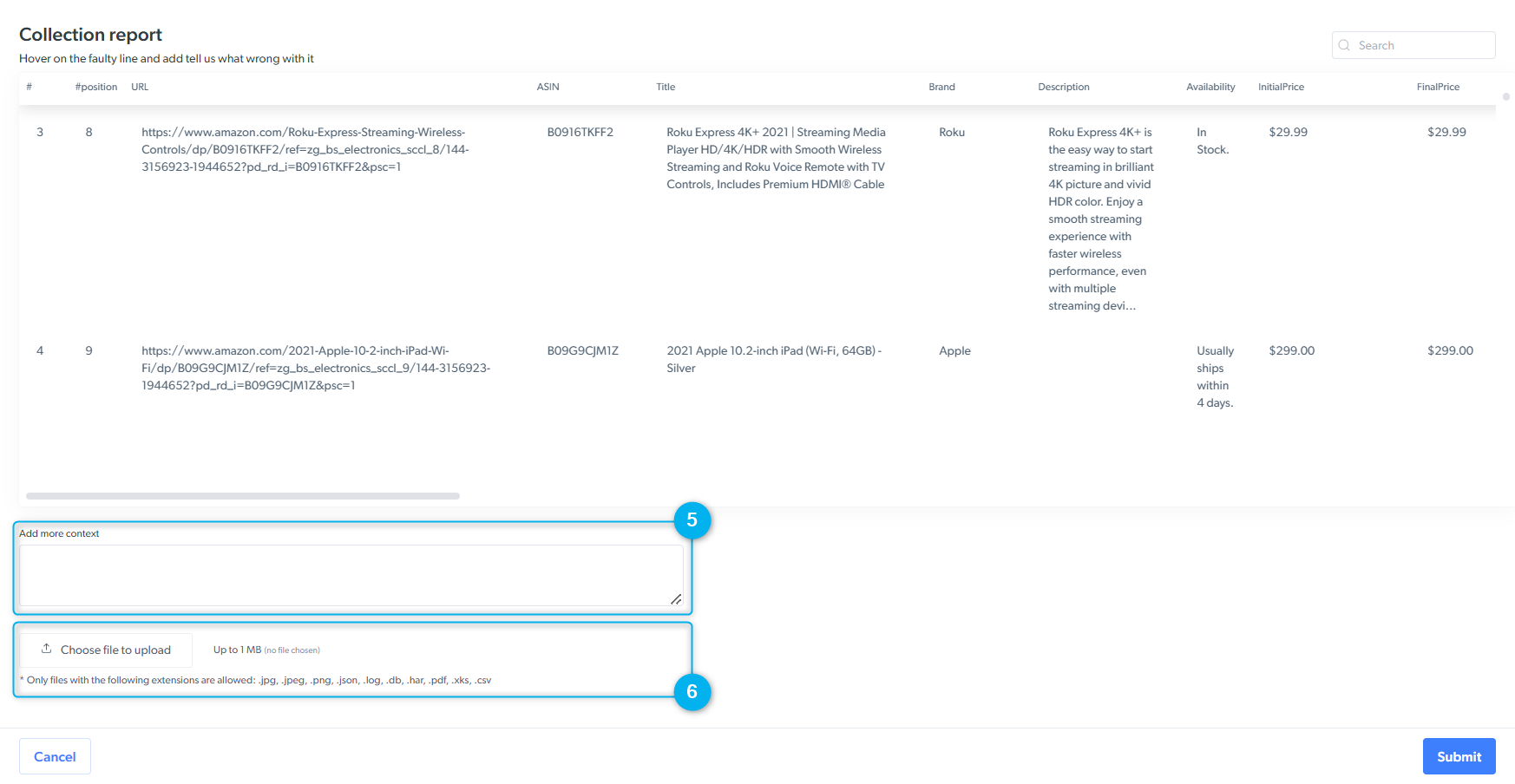
(Parsing issues) Use the “bug” red icon to indicate where the incorrect results are
(Parsing issues) Enter the results you expect to receive
Write a description of what went wrong and the URL where the data is collected
If needed, attach an image to support your report
I updated input/output schema of my managed scraper. Can I use it while BrightData updates my scraper?
I updated input/output schema of my managed scraper. Can I use it while BrightData updates my scraper?
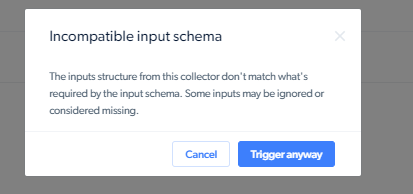
If you want to initiate it ignoring schema change, you can click ‘Trigger anyway’ on UI. API, you can add
- output schema incompatible:
override_incompatible_schema=1 - input schema incompatible:
override_incompatible_input_schema=1
How can I debug real time scrapers?
How can I debug real time scrapers?
What should I do if I face an issue with a Web Scraper?
What should I do if I face an issue with a Web Scraper?
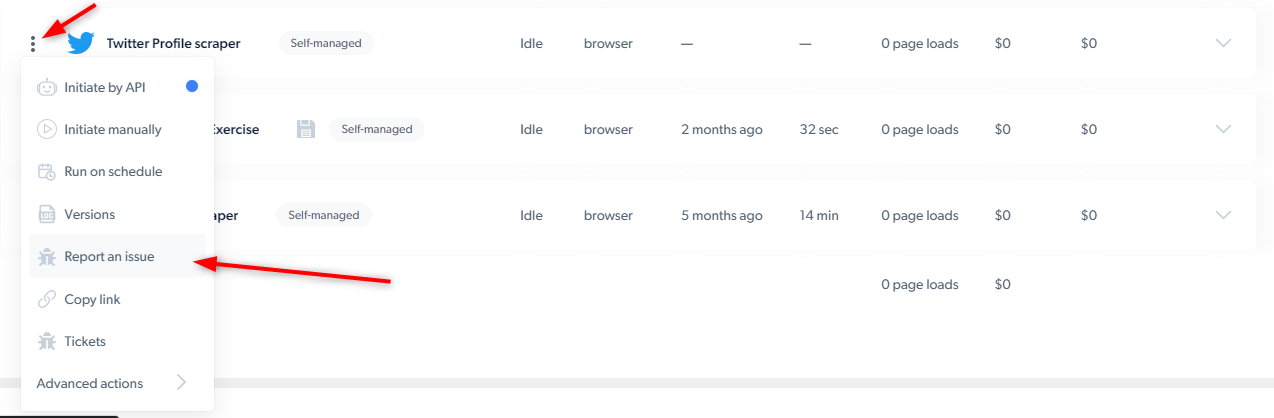
When “reporting an issue”, what information should I include in my report?
When “reporting an issue”, what information should I include in my report?
- Select the type of problem you’re facing (for example: getting the wrong results/missing data points/the results never loaded/delivery issue/ UI issue/scraper is slow/IDE issue/other)
- Please describe in detail the problem that you are facing
- You may upload a file that describes the problem
What is a Data Collector?
What is a Data Collector?
How to Create a Data Collector?
How to Create a Data Collector?
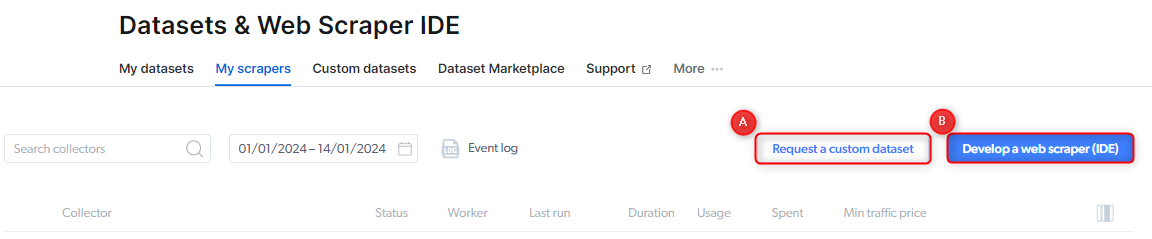
- Using the Web Scraper IDE: You can design and structure your parser as individual Collectors or as a single Collector with multiple steps. To get started:
- Click on the “Web Data Collection” icon on the right.
- Navigate to the “My Scrapers” tab.
- Select the “Develop a Web Scraper (IDE)” button.
- Requesting a Custom Dataset: If you prefer us to handle it, you can request a custom dataset, and we’ll create the Data Collectors needed to deliver it. To do this, click on the “Request Datasets” button under the “My Datasets” tab and choose the option that best suits your needs. Start here: Request a Custom Dataset
Any system limitations?
Any system limitations?
How do i use the AI code generator?
How do i use the AI code generator?
The goal of this feature is to generate a custom code template tailored to your target website. Simply enter the target URL, and we’ll automatically generate a ready-to-use code template that you can edit or run as needed.
How does it work?
Simply enter your target URL and click “Generate Code.” Once the code is ready, it will appear in the IDE tab - no need to wait around while the AI processes your request. You’ll receive an email notification as soon as the code is ready.
Note: This feature works on PDP (Product Detail Page) URLs - when you already know your target URL, it generates parser code accordingly. It is not ideally suited for “Discovery” use cases, where the goal is to find those target URLs.
For how long a snapshot is available after I triggered a collection?
For how long a snapshot is available after I triggered a collection?