What is a WARC file?
WARC is an ISO-standard file format (ISO 28500) for storing web crawls and HTTP interactions. A single WARC file contains the raw request and response pairs, headers, timestamps, and payload bytes from every browser-side fetch during page load, HTML, CSS, JavaScript, images, and XHR requests.WARC snapshots are available only on Browser worker scrapers. Code worker scrapers do not run a browser, so there is no browser-level network traffic to archive.
How do I enable WARC output on a scraper?
1
Open the scraper in the Bright Data Scraper Studio IDE
Go to brightdata.com/cp, select the scraper you want to archive, and click Edit code to open it in the IDE.
2
Enable the warc_snapshot field
In the Output Schema panel, find the 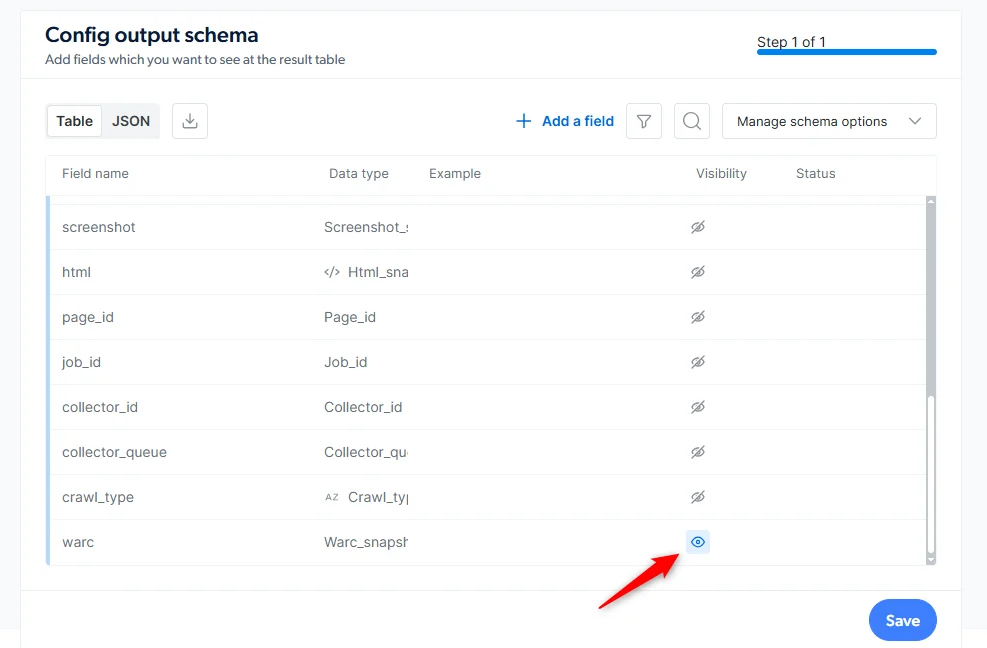
additional_data section and click the eye icon next to warc_snapshot to turn it on.3
Save and run a job
Save the scraper to production and trigger a run. The WARC file is produced for every page the scraper collects.
4
Retrieve the WARC files
Bright Data delivers the WARC files using whatever delivery method you configured for the scraper: API download, webhook, S3, Google Cloud Storage, Azure, SFTP, or email.See Initiate collection and delivery for delivery options.
How do I maximize what the WARC captures?
WARC capture records every request the browser makes during page load, but only while the browser is actively loading the page. To capture more, give the browser time to finish loading before the scraper moves on:- Call
wait_network_idle()near the end of the interaction code so the browser drains in-flight XHR and fetch requests before Bright Data Scraper Studio finalizes the WARC file. - Prefer Browser worker over Code worker. Only browser-worker network traffic is recorded; raw
request()calls in code-worker scrapers are not. - If the page lazy-loads media via scroll, call
scroll_to('bottom')orload_more()beforewait_network_idle()so the browser actually fetches those resources.
Frequently asked questions
What is recorded inside a Bright Data Scraper Studio WARC file?
What is recorded inside a Bright Data Scraper Studio WARC file?
Every browser-side request and response captured during page load: HTML documents, CSS, JavaScript, images, fonts, XHR, and fetch calls. Each entry includes the request line, headers, and response payload as the browser received them.
Does WARC output work with Code worker scrapers?
Does WARC output work with Code worker scrapers?
No. WARC snapshots require Browser worker because the capture runs at the browser network layer. Code worker scrapers issue raw HTTP requests directly, with no browser to record traffic from.
How are WARC files delivered and how much do they cost?
How are WARC files delivered and how much do they cost?
WARC files are delivered through the scraper’s configured delivery method (API download, webhook, cloud storage, SFTP, or email). File downloads are billed per GB, separately from CPM page loads. See Scraper Studio specifications for current rates.
How long does Bright Data keep WARC snapshots?
How long does Bright Data keep WARC snapshots?
WARC snapshots follow the scraper’s snapshot retention: 16 days for batch collections and 7 days for real-time collections. Export or download the files before the retention window closes. Bright Data does not recover expired data.
Related
Scraper Studio specifications
Billing model, retention periods and infrastructure limits
Initiate collection and delivery
Set the delivery destination for WARC files and collected data