What is the Scrapers?
What is the Scrapers?
Who can benefit from using the Scrapers?
Who can benefit from using the Scrapers?
How do I get started with the Scrapers?
How do I get started with the Scrapers?
What is the difference between the scrapers?
What is the difference between the scrapers?
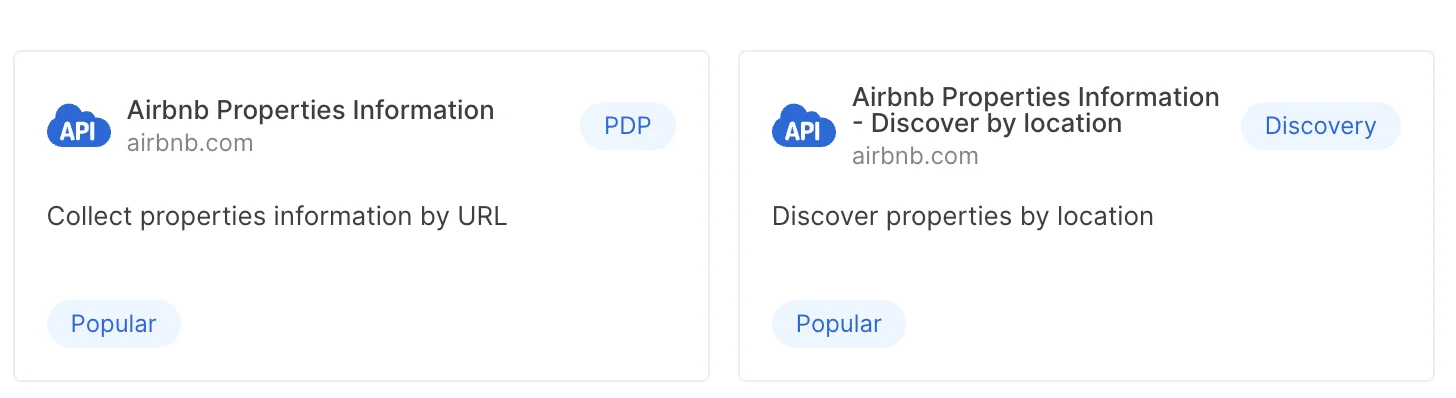
- PDP
These scrapers require URLs as inputs. A PDP scraper extracts detailed product information like specifications, pricing, and features from web pages - Discovery/ Discovery+PDP
Discovery scrapers allow you to explore and find new entities/products through search, categories, Keywords and more.
Why are there different discovery APIs for the same domain?
Why are there different discovery APIs for the same domain?
How do I authenticate with the Scrapers?
How do I authenticate with the Scrapers?
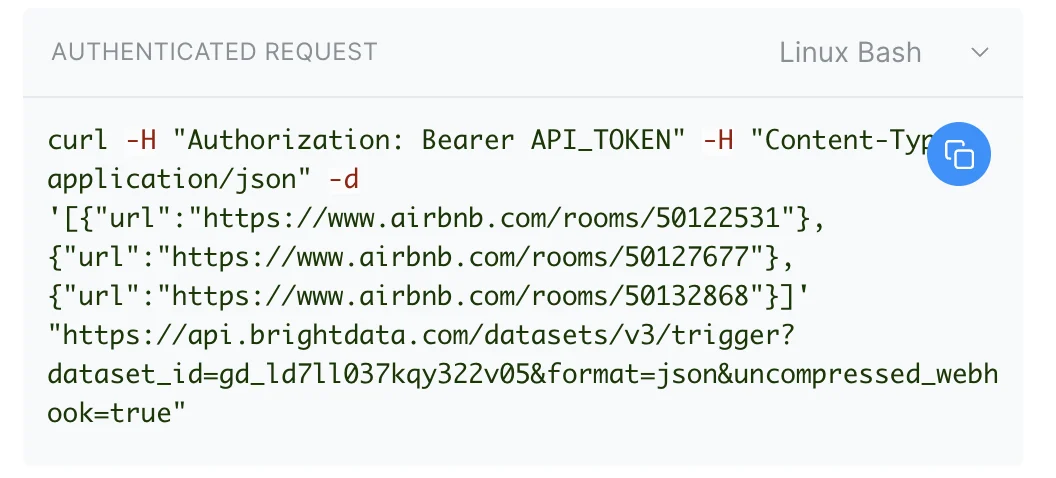
Authorization header of your requests as follows: Authorization: Bearer YOUR_API_KEY.How do I customize my request and trigger it?
How do I customize my request and trigger it?
Do you offer a free trial?
Do you offer a free trial?
How do I test the API?
How do I test the API?
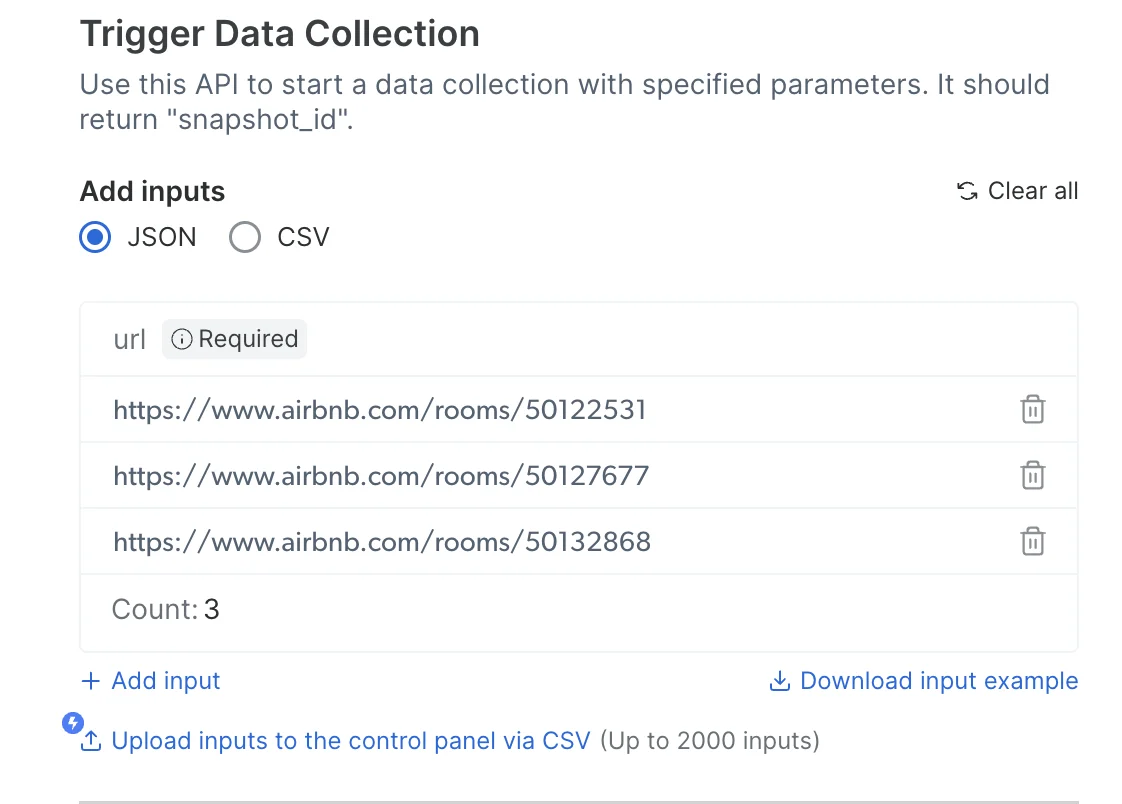

Select your preferred delivery method
S3, GCP, pubsub and more) and copy the code and run the code after collection endsCopy the code and run it on your client
What data formats does the Scrapers support?
What data formats does the Scrapers support?
JSON, NDJSON, JSONL and CSV. Specify your desired format in the request parameters.What are the rates for the Scrapers?
What are the rates for the Scrapers?
What should I do if my API key expires?
What should I do if my API key expires?


How does Scraper APIs manage large-scale data extraction tasks?
How does Scraper APIs manage large-scale data extraction tasks?
How can I upgrade my subscription plan?
How can I upgrade my subscription plan?
What specific use cases are Scraper APIs optimized for?
What specific use cases are Scraper APIs optimized for?
How fast is the Scrapers?
How fast is the Scrapers?
How do I cancel an API call?
How do I cancel an API call?
What is the difference between a notify URL and a webhook URL configurations?
What is the difference between a notify URL and a webhook URL configurations?
For how long a snapshot is available after i triggered a collection?
For how long a snapshot is available after i triggered a collection?
Are there any limitations for specific scrapers or domains?
Are there any limitations for specific scrapers or domains?
Facebook
| Posts (by profile URL) | |
| Comments | |
| Reels |
Instagram
| Posts (by keyword) | |
| Posts (by profile URL) | |
| Comments | |
| Reels |
Pinterest
| Profiles | |
| Posts (by keyword) | |
| Posts (by profile URL) |
Reddit
| Posts (by keyword) | |
| Comments |
TikTok
TikTok
| Profiles (by search URL) | |
| Comments | |
| Posts (by keyword) | |
| Posts (by profile URL) |
Quora
Quora
| Posts |
Vimeo
Vimeo
| Posts(by keyword) | |
| Posts(by URL) |
X (Twitter)
X (Twitter)
| Posts |
YouTube
YouTube
| Profiles | |
| Posts (by keyword) | |
| Posts (by URL) | |
| Posts (by search filters) |
TikTok
TikTok
Linkedin
What does it mean when a snapshot is marked as empty?
What does it mean when a snapshot is marked as empty?
- Errors: Issues encountered during the data collection process, such as invalid inputs, system errors, or access restrictions.
- Dead Pages: Pages that could not be accessed for reasons like 404 errors (page not found), removed content (e.g., unavailable products), or restricted access.
include_errors=true in your request, which will display the errors and information about the dead pages in the snapshot. This helps you diagnose and understand the issues within the snapshot.How to stop a web scraper task?
How to stop a web scraper task?
Which domains do you provide scrapers for?
Which domains do you provide scrapers for?
How can I use Bright Data to access hotel data through an API?
How can I use Bright Data to access hotel data through an API?
How do I get the data I need?
How do I get the data I need?
- Option 1: Enriched, Pre-Collected Data – Explore Our Datasets Marketplace
How do I scrape data from google maps?
How do I scrape data from google maps?
- Find the “Google Maps reviews” scraper on the dashboard and choose if you want to run it as an API request or initiate it using the “No code” option from the control panel
- Enter the input parameters (The place page URL and, Number of days to retrieve reviews from)
- Configure the needed request parameters if using an API
- Initiate the run and collect the data
How do I cancel a running snapshot?
How do I cancel a running snapshot?
- API Request:
-
Send a
POSTrequest to the endpoint: POST /datasets/v3/snapshot/cencel (playgrownd) -
Replace
{snapshot_id}with the ID of the snapshot you want to cancel.
-
Send a
- Control Panel:
- Go to the Logs tab of the scraper.
- Locate the running snapshot.
- Hover over the specific run and click the “X” to cancel it.
Does the chatGPT scraper works with “SearchGPT” active?
Does the chatGPT scraper works with “SearchGPT” active?
Can I view the code behind the scraper?
Can I view the code behind the scraper?
For those interested in seeing how scrapers work, the Web Scraper IDE provides several example templates when you create a new scraper. These examples serve as practical references to help you understand scraping techniques and build your own custom solutions.
Can i get the results directly to my machine or software while using the Scrapers?
Can i get the results directly to my machine or software while using the Scrapers?
Using the following endpoint -
POST api.brightdata.com/datasets/v3/scrapeThis endpoint allows you to fetch data efficiently and ensures seamless integration with your applications or workflows.
How does it works?
The API enables you to send a scraping request and receive the results directly at the request point. This eliminates the need for data retrieval or the need to send to external storage, streamlines your data collection process.
Limitations
What is a dataset id and where can I find it?
What is a dataset id and where can I find it?
https://api.brightdata.com/datasets/v3/trigger?dataset_id=DATASET_ID_HEREA dataset id will look like: gd_XXXXXXXXXXXXXXXXX For example: gd_l1viktl72bvl7bjuj0You can find the exact dataset ID in two places:- In the browser URL bar when viewing a scraper page, it appears as
/cp/scrapers/gd_xxx - In the Code examples panel on the scraper’s Configuration tab, it is pre-filled in the curl command, ready to copy.
s_XXXXXXXXXXXXXXXXXXfor example: s_m7hm4et0141r2rhojq is not a dataset ID, it is a snapshot id - a snapshot is a collection of data that is collected from a single Scrapers request.What is 'Discovery only' mode?
What is 'Discovery only' mode?
For example, if an Amazon product discovery scraper is initiated in Discovery-only mode, it will return only the product URLs found during the discovery phase. When this mode is turned off, the scraper will continue to visit and extract data from each individual product page identified during discovery.
Is there an option to rerun failed snapshots?
Is there an option to rerun failed snapshots?
How to retrieve your original inputs?
How to retrieve your original inputs?
YOUR_API_KEYwith your actual API keysd_XXXXwith your snapshot ID
What is the difference between 'Synchronous (Real-time)' and 'Asynchronous' in the UI?
What is the difference between 'Synchronous (Real-time)' and 'Asynchronous' in the UI?
| UI Label | API Endpoint | Use when |
|---|---|---|
| Synchronous (Real-time) | POST /datasets/v3/scrape | You need instant results for 1–20 URLs |
| Asynchronous | POST /datasets/v3/trigger | You’re processing bulk URLs, discovery tasks, or large datasets |
Where do I get a Snapshot ID?
Where do I get a Snapshot ID?
/datasets/v3/trigger), filter a dataset (POST /datasets/filter), or via a dataset subscription. You can also list all your snapshots with GET /datasets/v3/snapshots.What do I do with the delivery job ID in the response?
What do I do with the delivery job ID in the response?
id in the response is a delivery job ID. Use it to track delivery progress by calling GET /datasets/v3/delivery/{delivery\_id}. Poll until status is “done”.Does the snapshot need to be in a specific status?
Does the snapshot need to be in a specific status?
ready status. Check with GET /datasets/snapshots/{id} before calling deliver. Possible statuses: scheduled, building, ready, failed.Can I deliver the same snapshot to multiple destinations?
Can I deliver the same snapshot to multiple destinations?
What file formats are supported?
What file formats are supported?
json, jsonl, and csv.How do I split large snapshots into smaller files?
How do I split large snapshots into smaller files?
batch_size parameter to set the number of records per file. Each file (batch) must stay under the 5GB hard limit. Estimate batch_size by dividing 5GB by your average record size, then start lower and adjust based on the actual file size you get.For example, if your average record is ~5KB, a batch_size of 1,000,000 records lands right at the ~5GB limit. Start at 500,000 records (~2.5GB) to stay safely under, then raise or lower batch_size based on the file size you receive.Why did my request return a 400 error?
Why did my request return a 400 error?
batch_size produces a file larger than 5GB. For example, if your average record size is ~5KB, a batch_size of 1,000,000 produces a ~5GB file that may exceed the limit. Lower your batch_size (e.g., to 100,000) and retry.Can I compress the output?
Can I compress the output?
compress: true to receive gzip-compressed files.What is the maximum file size per batch?
What is the maximum file size per batch?
batch_size to control how many records go into each file and ensure each stays under this threshold.