Questions? Click here to contact us >>>
June 14, 2026
⚠️ Known Issue
Grok Scraper temporarily unavailable
The Grok Scraper is unavailable again as of June 14, 2026, due to a renewed blocking issue on Grok’s side. Bright Data is actively monitoring the situation and will restore the Grok Scraper as soon as it becomes accessible again.June 11, 2026
✨ New Features
Grok Scraper available again
The Grok Scraper is available again as of June 11, 2026, after the earlier blocking issue on Grok’s side was resolved.Google 100 Scraper is back online
The Get Top 100 Google Results feature, which returns Google SERP positions 1-100 in one request, is back online as of June 11, 2026.June, 2026
✨ New Features
Free tier: 5,000 free credits every month
Every new Bright Data account now gets 5,000 free credits per month, a single shared pool usable across the Unlocker API, SERP API, Web Scraper API and Scraper Studio. No credit card required. Credits renew on the first of each month, and the Bright Data MCP server free tier draws from this same pool. Learn more.⚠️ Known Issue
Top 100 Google Results temporarily unavailable
The Get Top 100 Google Results feature, which returns Google SERP positions 1-100 in one request, is currently unavailable due to blocking issues on Google’s side. Bright Data is actively monitoring the situation and will restore the feature as soon as it becomes accessible again.May, 2026
⚠️ Known Issue
Grok Scraper temporarily unavailable
The Grok Scraper is currently unavailable due to a blocking issue on Grok’s side. Bright Data is actively monitoring the situation and will restore the Grok Scraper as soon as it becomes accessible again.📘 Docs
Clarified exclusive to semantics for GET /zone/cost
- The
toquery parameter is exclusive. The day specified is not included in the result. To match a calendar month shown in the Control Panel or on your invoice, settoto the first day of the following month. See the updated docs.
🚀 Improvements
LLM Scrapers
- Updated supported countries for LLM Scrapers: We have revised the list of supported countries across all LLM scrapers (ChatGPT and other answer engines). View the full list.
April, 2026
✨ New Features
Web Scraper API: Success Rate (SR) Email Alerts
Web Scraper API: Success Rate (SR) email alerts are now available in the Control Panel. Learn MoreMarch, 2026
✨ New Features
New field for Scraper: ChatGPT
R&D added a new field to the output schema:prompt_sent_at.This field allows customers to know the exact time the scraper clicks “Send” to submit the prompt. Until now, we only provided a timestamp for when the Bright Data Web Scraper API received the request, not when the prompt was actually executed.WSAPI Google SERP - 100 Results
- New
collapse_aioparameter: Setcollapse_aio=trueto return the SERP with the AI Overview (AIO) section collapsed. This enables more stable and comparable layout and pixel-position measurements by preventing AIO from pushing organic results down the page. Default isfalse(AIO expanded). Learn more
Browser API - Session ID & Session Logs
- New
Browser.getSessionIdCDP command: Retrieve the unique session ID of your current Scraping Browser session. Useful for investigating errors, unexpected behavior, or high bandwidth usage via the Session Logs API. Learn more - New Session Logs API endpoints:
GET /browser_sessions, List and filter browser sessions by status, date range, target URL, bandwidth, and more. Learn moreGET /browser_sessions/{session_id}, Retrieve details for a specific browser session. Learn more
January, 2026
Release Notes for Week Ending January 6, 2026
✨ New Features
Model Context Protocol (MCP)
- Custom MCP Configuration: Fine-tune your AI agents by selecting only the necessary tools from 60+ specialized options (E-commerce, Social Media, Travel, etc.) to optimize performance and reduce token usage. Includes built-in unlocking and CAPTCHA solving. Try now
- One-click MCP Connection: Instantly connect to the MCP Free Tier with zero configuration. Link to Claude, Cursor, or Visual Studio Code with a single click. Try now
✨ New Features
Web Unlocker
- Unlock Fragmented URLs in a Single Call: Directly unlock URLs containing fragments (the # character) via the Unlocker API, eliminating the need for workarounds.
- REST API: Simply provide the fragmented URL(e.g.
https://www.somesite.com/#!/path1/id11133/9*Fmt=100). Response time may be slightly longer due to increased processing. - Native API: Use the new
x-unblock-url-fragmentheader to pass the fragment portion. Learn more
- REST API: Simply provide the fragmented URL(e.g.
✨ New Features
SERP API
- Google Trends Support: Extract trending data using new dedicated parameters (e.g.,
brd_trends=timeseries,geo_map) to retrieve widget-specific data like time-series and geographic visualizations. Supports “Trending now” with options for geo-targeting, time ranges, categories, and search types. - Google Reviews Scraping: Collect Google Reviews data with full control over targeting, localization, sorting, filtering, and pagination.
- Google Lens Integration: Search by image using Google Lens. Supports image URLs, file uploads, localization, and exact match filtering.
- Google Hotels Data Extraction: Access hotel search results with support for localization, booking dates, room options, and multiple output formats.
- Google Flights Data Extraction: Retrieve flight search data with full localization support and comprehensive flight details. Learn more
✨ New Features
Residential Proxies
- Request Peers with Guaranteed Minimum Session Lifetime: Use the new
min_ttlparameter (1-60 minutes) to request residential peers estimated to remain online for a specified duration, ideal for extended sessions where IP changes are disruptive.
🚀 Improvements
Proxy Infrastructure
- Expanded ISP Proxy Capacity: Added approximately 200,000 new ISP IPs for increased pool diversity and reduced rotation pressure during high-volume operations.
- Smarter Datacenter Load Balancing: Improved the bandwidth metrics algorithm for datacenter proxy load distribution, resulting in better traffic allocation.
- New Error Code for Destination Timeouts: Added a dedicated
brd_errorcode for “Destination host connect timeout” errors for clearer distinction between proxy and target site connectivity issues. - Faster System Alert Delivery: Optimized email notification system for network status alerts, ensuring prompt delivery upon service disruptions or restorations.
- Enhanced Tunnel Agent Logging: Added
p_dcandp_agentfields to proxy logs for better visibility into the datacenter and agent handling each request, improving debugging and performance analysis.
🐞 Bug Fixes
Proxy Infrastructure
- Fixed IP Range Preset Management in Dashboard: Resolved issues where removing IP range presets didn’t update the UI, loading states weren’t displayed, and some presets weren’t visible in the table view.
- Fixed Data Inconsistency During Error Resolution: Resolved a race condition that caused data inconsistency when resolving alert errors, making monitor status updates atomic and reliable.
- Improved Proxy Agent Error Logging: Fixed an issue where probe timeout errors logged
[object Object]instead of diagnostic information. Error logs now include the connection ID and relevant details. - Fixed Tunnel Action Documentation Tooltips: Added explanatory tooltips to tunnel server actions in the internal documentation, including guidance on checking affected customers when removing IP ranges.
⚠️ Deprecations
SERP API
- Google Maps Pagination Parameters Deprecated: The
startandnumpagination parameters for Google Maps were deprecated on December 15th, 2025.- Recommended alternative: Use the Scrapers’s Google Maps Scraper for full coverage of all search results.
- Access Scraper (requires login):
https://brightdata.com/products/web-scraper/google-maps. Learn more
December, 2025
Release notes for week ending December 19, 2025
✨ New Features
Deep Lookup
- Enrich your own entity lists directly in Deep Lookup: You can now bring your own list of entities and enrich them directly within Deep Lookup. Whether you’re discovering new entities or enriching ones you already have, Deep Lookup is now your complete enrichment platform, all in one place.
✨ New Features
Web Unlocker
- Unlock fragmented URLs in a single call: You can now unlock URLs containing fragments (the # character) directly through the Unlocker API, no workarounds needed. Learn more
- REST API: Simply provide the fragmented URL and Bright Data Unlocker handles the rest. Response time may be slightly longer due to increased processing.
- Native API: Use the new x-unblock-url-fragment header to pass the fragment portion of your URL.
✨ New Features
Residential Proxies
- Request peers with guaranteed minimum session lifetime: You can now request residential peers that are estimated to remain online for a specified duration. Use the new
min_ttlparameter (1-60 minutes) to get peers that will stay connected longer, ideal for extended browser sessions and multi-step scraping jobs where mid-session IP changes would disrupt your workflow.
✨ New Features
SERP API
- Configure default data format in zone settings: You can now set your preferred default data format (JSON, HTML, etc.) directly in your SERP API zone configuration. This eliminates the need to specify the format header on every request, just set it once and all requests will use your preferred format automatically.
🚀 Improvements
Datasets
- Up to 85% faster checkout: Dataset purchases that previously took 15-30 seconds now complete in just 2-5 seconds. Enjoy a much snappier buying experience with dramatically reduced checkout latency.
- Expanded e-commerce data coverage: We’ve significantly grown the Bright Data product catalog across key e-commerce datasets:
- Wayfair: 6M → 15M products (+150%)
- Amazon Global: 35M → 85M products (+143%)
- Google Shopping: 84M → 113M products (+35%)
- Amazon Products US: 310M → 374M products (+20.6%)
- Higher data quality with improved validation: A new validation flow for full datasets ensures higher data quality before delivery. This enhancement is currently rolling out across our data pipelines.
🚀 Improvements
Proxy Infrastructure
- Expanded ISP proxy capacity in US regions: Added over 300,000 new ISP IPs across key US locations including Dallas, Los Angeles, and Ashburn, giving you more IP diversity and reduced rotation pressure for high-volume operations.
- Faster detailed statistics loading: Optimized the bank statistics service to eliminate timeout issues when loading detailed stats reports. You’ll experience more reliable access to your proxy usage analytics.
- Reduced latency during proxy bank updates: Optimized the DC proxy bank processing to eliminate lag spikes during index updates. Your requests now maintain consistent low latency even during background data refreshes.
🚀 Improvements
Control Panel
- Unified proxy list download experience: We’ve streamlined how you download proxy lists across the Control Panel. All download locations now offer the same consistent experience with multiple format options:
- Colon-separated:
host:port:usr:pwd or usr:pwd@host:port - CSV:
host,port,usr,pwd(with optional location data) - IP list: single column with IPs
- Colon-separated:
- Downloads now include timestamps in filenames to prevent overwrites, and you’ll see a preview before downloading. A security warning reminds you to keep your proxy credentials safe.
🐞 Bug Fixes
Datasets
- Fixed missing enriched fields in exports: Resolved an issue where enriched fields were missing when downloading datasets in CSV or JSON format. All enriched data now exports correctly, ensuring your downloads contain the complete dataset you expect.
🐞 Bug Fixes
Proxy Infrastructure
- Fixed session drops for persistent connections: Resolved an issue where sessions with const=true were incorrectly dropped mid-job when peers temporarily disconnected. Your persistent sessions now maintain IP consistency as expected throughout browser jobs and extended scraping tasks.
- Fixed IP range preset management in dashboard: Resolved issues where removing IP range presets didn’t update the UI correctly and some presets weren’t displaying in table view. The static IP management interface now reflects changes immediately.
- Fixed data inconsistency during error resolution: Resolved a race condition that could cause data inconsistency when resolving alert errors. Monitor status updates are now atomic, ensuring reliable alert state management.
- Improved proxy agent error logging: Fixed an issue where probe timeout errors logged
[object Object]instead of useful debugging information. Error logs now include the connection ID and relevant diagnostic details for faster troubleshooting.
Release notes for week ending December 02, 2025
🚀 Improvements
Browser API
Expanded C# support for CAPTCHA solving: We have added dedicated examples for C# developers using PuppeteerSharp and Playwright. You can now copy-paste ready-made code to handle CAPTCHA challenges directly from the documentation.Proxy Network
Unified proxy list export: Export your proxy lists with a consistent experience. You can now easily choose your preferred format (CSV, TXT, or IP-only) and customize delimiter styles for faster integration. Just go to “My Proxies” -> choose a proxy -> In the “Overview” tab, click “Download” -> Choose format -> Click “Download”. Or, in the “Overview” tab, click “View” -> Click “Download” -> Choose format -> Click “Download”.Identify abrupt disconnects: Added new error code client_10140 to signal “brute client disconnects”. You can now distinguish when a connection was forcibly terminated by the client side rather than a network error, aiding in faster debugging.🐞 Bug Fixes
Web Unlocker
Accurate header usage logging: Corrected a reporting issue in system logs; the custom_expect field now accurately reflects when your custom headers or cookies are actively utilized by the Web Unlocker logic.Proxy Network
Clarified SOCKS5 port errors: Fixed an issue where attempting to use a disallowed port via SOCKS5 returned an incorrect error message. You will now receive accurate feedback to debug connection strings faster.Corrected IP assignment alerts: Resolved a bug where failed dedicated residential proxy assignments triggered the wrong email notification. You will now receive the correct alerts if an allocation fails, ensuring you can react immediately.November, 2025
Release notes for week ending Nov 14, 2025
🚀 Improvements
Clearer guidance when approaching usage limits: Improved alert emails now provide straightforward explanations of your usage status and next steps to help you manage your unlimited proxy plans effectively.Distribute unlimited proxy traffic freely across zones: Use your fair use allowance across all zones of the same type instead of per individual zone, reducing the risk of unexpected overages while one zone sits idle.Easier debugging with industry-standard error reporting: Proxy error information now follows RFC 9209 standards, making it simpler to integrate monitoring tools and troubleshoot issues. Legacy error headers will be deprecated in 2026 review the migration guide if you rely on custom error handling.October, 2025
Release notes for week ending Oct 31, 2025
🆕 New features
Scrapers
New social media scrapers: You can now collect data from Facebook profiles, Reddit profiles, and Reddit posts within a specific community (subreddit).New YouTube scrapers: We’ve added new scrapers for YouTube, allowing you to collect data from YouTube Podcasts and the YouTube Explore page, focusing on news content.Goodreads reviews scraper: A new scraper is available to collect book reviews from Goodreads.Proxy
IP Country Verification Endpoint: You can now use a dedicated endpoint to check the country that Google associates with a specific IP address, helping you verify geolocation for your requests.Browser Automation
Automation scripts that don’t break when sites update: Your browser automation continues working even when websites redesign their pages or change their structure. Spend less time fixing broken scripts and more time using your data.MCPKeep your automation data separate and clean: When running multiple MCP browser sessions at once, each operates in complete isolation, no data mixing, no session conflicts, just reliable parallel operations.🚀 Improvements
Scrapers
Google num=100 is gone, but your top‑100 isn’t: 1 request, 10x fewer calls: Get the top 100 Google results with the Scrapers (SERP100), no pagination, set language/country and depth, and get the original SERP HTML for audit. Cut request volume by up to 10x. Learn moreFaster, more reliable E-commerce data collection: Experience faster data retrieval from Amazon, Etsy, and eBay with fewer errors and timeouts. Your scraping jobs complete more quickly with more complete and accurate results.Quicker Captcha resolution: Your requests spend less time waiting when captchas appear. Reduced delays mean faster data collection and more efficient scraping operations.Release notes for week ending Oct 10, 2025
🆕 New features
Test Web MCP without any setup: Explore what’s possible with our Web MCP directly in your browser. No installation or configuration required. Run live scraping tests, experiment with different targets, and see results instantly before integrating into your workflow. Try nowStart building in minutes, not hours: Integrate Bright Data directly into your Python or NodeJS applications with native Python SDK and JavScript SDK designed for your workflow. Get autocomplete, type hints, built-in error handling, and comprehensive examples in the language you already use.🚀 Improvements
Find the exact data you need faster: Filtering large datasets is now quicker and more intuitive. Select multiple criteria at once, pick date ranges more easily, and get to your refined dataset in fewer clicks.🐞 Bug Fixes
Smoother filtering experience: Fixed issues that interrupted your workflow when refining dataset filters, including problems with clearing selections and unexpected page scrolling.September, 2025
Release notes for week ending Sep 30, 2025
🆕 New features
Datasets
Quick Filtering for datasets: Start filtering immediately with commonly-used options always at your fingertips. Type to get instant autocomplete suggestions, or describe what you need in plain language and let AI build the filter for you.Automate Web Archive delivery to Azure: Send Web Archive data directly to your Azure storage, eliminating manual downloads and uploads. Your data flows straight into your existing cloud infrastructure where your team already works.🚀 Improvements
Datasets
Understand Dataset fields instantly: No more guessing what cryptic field names mean. Dataset filters, previews, and documentation now use plain-language labels that clearly describe what each field contains, so you spend less time deciphering and more time analyzing.No more guessing about “Empty” updates: When your scheduled dataset refresh finds no new or changed data, you’ll now see a clear “No changes detected” status and receive an email explaining what happened with an option to trigger a full refresh if you prefer.Scrapers
Capture all Amazon reviews, not just text-based ones: Get a fuller picture of product sentiment by collecting reviews that appear in image galleries. Your Amazon review data now includes feedback that was previously hidden in carousel sections.Track scraper jobs without switching tools: When running synchronous requests, you now get a clickable link in your command-line response that takes you directly to the job monitoring page no need to manually navigate or search for your job.🐞 Bug Fixes
Scrapers
Collect all Glassdoor reviews without gaps: Fixed an issue where some reviews would be skipped during collection. Your Glassdoor scraping jobs now retrieve complete review sets more consistently.Fixed empty results for products with reviews: Resolved an issue where the Amazon scraper would return no data even when products clearly had customer reviews. Your Amazon review collections are now more reliable.Web Archive
Search large Web Archive datasets without timeouts: The Web Archive/webarchive/search endpoint now returns a search_id immediately. So, you can now query large datasets and track search progress in real-time without interruption.Release notes for week ending Sep 28, 2025
🆕 New features
Get Web MCP running with your AI tools in minutes: Find everything you need to integrate Model Context Protocol in one place, step-by-step setup guides for Claude, ChatGPT, Cursor, LangChain, and more, plus ready-to-use examples from the community. Learn moreRelease notes for week ending Sep 19, 2025
🚀 Improvements
Complete account verification (KYC) faster: Account verification is now more straightforward with clearer instructions and a simpler step-by-step process. Get verified and access your account more quickly. Learn moreHigher success rates for Google scraping: Collect data from Google with fewer interruptions. Improved unblocking techniques result in more consistent, reliable scraping performance.🐞 Bug Fixes
Better Safari browser emulation: Fixed an issue that could cause requests using Safari browser profiles to be detected or blocked. Safari-based scraping now works more reliably.Release notes for week ending Sep 12, 2025
🚀 Improvements
More predictable unlimited plan usage: Fair use limits for unlimited Datacenter and ISP plans now apply across all your zones combined, giving you more flexibility in how you distribute traffic and reducing the risk of unexpected overage charges.Find what you need faster in the Control Panel: Redesigned navigation makes it quicker to access your zones, datasets, scrapers, and settings. Rolling out to all new users now, with existing users gaining access in December.August, 2025
Release notes for week ending Aug 31, 2025
🆕 New features
Datasets
Filter thousands of records at once: Upload a CSV or JSON file to filter datasets by large lists of values, no need to manually enter hundreds of product IDs, URLs, or other criteria. Perfect for bulk operations and matching datasets to your existing data.See enriched data instantly, filter before you buy: Datasets with additional enrichment (like LinkedIn profiles with company information) now load and preview immediately. Filter by enriched fields to validate the data meets your needs before purchasing.Scrapers
Monitor e-commerce pricing on three major platforms: Collect current prices and stock availability from Coupang, Amazon, and Walmart to track competitors, validate pricing strategies, or analyze market trends.Scrape complete hotel data from Google: Collect everything from basic details (name, location, star rating) to booking information (prices, availability, trends), guest insights (reviews, ratings), and amenities, all from Google’s hotel listings.🚀 Improvements
Datasets
Delivery progress indicator: Track your data deliveries in real time, see exactly how far along your dataset deliveries are with live progress updates in the Control Panel. No more guessing when your data will be ready.Quicker SFTP transfers: Your datasets now transfer to SFTP destinations faster, reducing wait times for large data deliveries.Less alert noise, clearer information: When delivery issues occur, you’ll now see one consolidated notification with all the details instead of multiple separate alerts cluttering your Dashboard.Smarter delivery rate limiting: A new rate limiter for data deliveries has been implemented to improve stability, with a default of 100 concurrent deliveries and per-customer configuration available.Scrapers
Troubleshoot scraper errors faster: Find clear explanations for every Scrapers error code in our documentation. Understand what went wrong and how to fix it without contacting support.🐞 Bug Fixes
Datasets
Dataset preview table no longer shows as empty: Fixed an issue where the preview table would appear blank even when the dataset contained data. Your dataset samples now display correctly every time.CSV filtering handles empty lines: Removed errors when filtering with CSV files that contain blank rows.Release notes for week ending Aug 29, 2025
🆕 New features
Instant support in Chinese: Get immediate help in your language when visiting bright.cn. Our AI assistant Sophie provides instant answers in Chinese, with seamless handoff to live support agents during business hours when you need more help.Release notes for week ending Aug 22, 2025
🚀 Improvements
Proxy Network Simplification: Streamlined zone settings by removing rarely-used option “Cache proxy”, making it easier to configure exactly what you need without confusion.🐞 Bug Fixes
Better readability in dark mode: Fixed display issues that made parts of the Control Panel difficult to read or visually inconsistent when using dark mode.
Release notes for week ending Aug 8, 2025
🆕 New features
MCP Playground: Test and interact with the new interactive MCP playground. This feature allows you to send and receive messages to test crawler logic. Try nowProtection against accidental account deletion: Changed account to “deactivate” instead of deleting immediately? You now have 30 days to change your mind and reactivate. Plus, your account manager will reach out to understand what went wrong and help if you’re facing issues. Learn more🚀 Improvements
Test any API before committing: Try Proxy networks, Web Unlocker and SERP API in the Control Panel for FREE! Validate your use case and see real results before writing your integration code. Try nowGet to human support in one click: When you ask to speak with someone, BrightAI now provides a direct link to create a support ticket, ensuring your issue gets proper attention and tracking instead of getting lost in chat.July, 2025
Release notes for week ending Jul 29, 2025
🆕 New features
IP Orders for Verified Accounts
Order large quantities of dedicated IPs with processing time and delivery tracking. Read moreDeep Lookup Preview Mode
Preview table structure for free before pulling data, with a built-in co-pilot to refine prompts for better accuracy. Read moreLight Parser for Google
Parse top 10 search results up to 2.5× faster for quicker responses. Read moreBing → Bright Data SERP API Migration
1-to-1 migration path for moving Bing API parsing to Bright Data’s SERP API. Read moreRelease notes for week ending Jul 22, 2025
🆕 New features
Scrapers – Gemini/Grok/Google AIO
Added AI Scraper support for multiple models, making it easier for users of one AI scraper to leverage others. Read moreBrightAI Start Page
Introduction of BrightAI, a RAG-based assistant that uses account logs and settings to guide users through setup, optimization, and navigation of Bright Data tools.Data and Data Rate Overview
New filters on the Zone Dashboard provide insights into traffic volume and connection speed by zone, type, and target domain for better optimization and anomaly detection. Read moreResidential Mega Pool
Access to a larger pool of rotating IPv4 and IPv6 residential proxies.IPv6 to IPv4 Failover
Automatic fallback to IPv4 when target sites don’t support IPv6, improving success rates.Datacenter and ISP Bulk Orders
Selected customers can place future orders for dedicated datacenter and static residential proxies with delivery tracking in the control panel.MCP Cloud Storage
Option to use cloud-hosted or self-hosted MCP for broader compatibility. Read moreWeb Archive Prefix Customization
Ability to set a custom prefix for the top-level export folder path. Read moreJune, 2025
May, 2025
🆕 New features
Residential network: IPv6 support
You can now use IPv6 on Bright Data’s residential network. With 150,000+ IPv6-enabled peers and growing, this upgrade offers greater scalability and access to a larger IP pool. Read more.Custom Scrapers
Easily extract data from any website, no coding or infrastructure needed. Just provide target URLs and define the data you want. Choose to manage the project yourself or let us handle it end-to-end. Read more.Scrapers: custom field selection
Save storage and streamline output by selecting only the fields you need using a simple pipe-separated list. Read more.🚀 New Integrations
LangChain
Power LLM agents with real-time, anonymous web data. Read more.Lindy.ai
Enable AI “employees” to automate tasks using live web data. Read more.LlamaIndex
Ingest and index web data seamlessly into your knowledge base to enable powerful retrieval-augmented generation (RAG) workflows. Read more.Make
Automate scraping, dataset retrieval, and API calls, no code required. Read more.n8n
Build automated workflows that connect Bright Data’s capabilities with hundreds of other apps and services, all with a visual editor. Read more.April, 2025
Release notes for week ending Mar 20, 2025
Datasets
🆕 New features
Large Dataset Splitting and Download in UI: You can now download large datasets directly from the UI. Large files are automatically split into smaller parts with easy download links through the email, making big data access smoother and more convenient.🚀 Improvements
- Improved Delivery System: We made backend improvements to ensure faster and more reliable dataset deliveries.
- Filter API Tweaks: We fine-tuned the Filter API for better performance and more accurate filtering.
- Support for Free Datasets: We added billing-side support for free datasets, making it easier to access datasets that are available at no cost.
Error Status Documentation Added
We updated our documentation to include error status codes for the Dataset API, helping developers troubleshoot issues faster.👉 View Documentation
Download Large Snapshots via Email
You can now receive an email with download links for snapshots larger than 5GB, offering another easy way to access big datasets.Snapshot Metadata API Update
The Snapshot Metadata API now returns error details, error codes, and initiation type, giving you better visibility into your dataset operations.🐞 Bug Fixes
- Fixed “Custom Dataset” Button: The “Custom Dataset” button now works properly.
- Fixed Parquet Delivery “Out of Memory” Error: Large Parquet file deliveries no longer cause memory errors.
- Fixed Filter Issues
- Missing “list exact match” and “include” options in filters were fixed.
- Filtering issues for the Enriched Employee Business dataset were resolved.
- Unclear filter error messages in the UI are now clearer and more helpful.
- Fixed Snapshots Table UI: The snapshots table now displays correctly without empty columns.
March, 2025
Release notes for week ending Mar 20, 2025
General:
🆕 New features
- AI-Powered Support
- BrightAI now serves as the first responder to support tickets for small and new customers, providing immediate assistance while maintaining our commitment to quality service. You’ll receive faster initial responses, but rest assured that you can request a human support specialist at any point during your conversation if needed.
Datasets:
🆕 New features
- Easier Filtering with Auto-Complete
-
Filtering datasets is now faster and more intuitive with auto-complete suggestions. For example, when selecting an Amazon category, you can now choose from a predefined list instead of searching manually on Amazon.
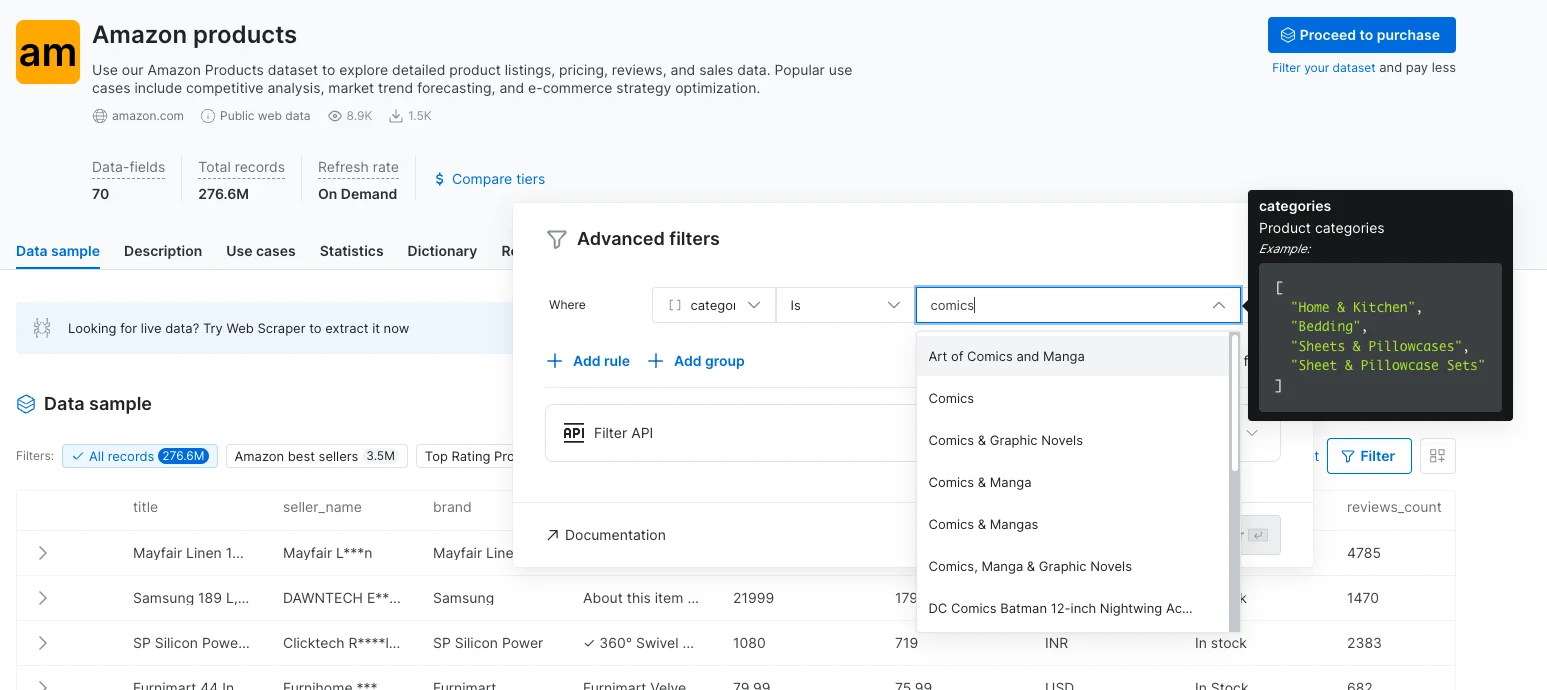
-
Filtering datasets is now faster and more intuitive with auto-complete suggestions. For example, when selecting an Amazon category, you can now choose from a predefined list instead of searching manually on Amazon.
- New API for Dataset Metadata
- Developers can now access dataset metadata through our API, making it easier to integrate with automation tools like Zapier, Make.com, and n8n.io. This allows you to retrieve dataset details and schema to set up automated workflows and get the exact data you need. 👉 View API Documentation (link)
🚀 Improvements
- Better Search in the Marketplace
-
Searching for datasets is now more flexible, allowing for slight variations and even typos. This makes it easier to find what you need, even if your search isn’t perfectly accurate.
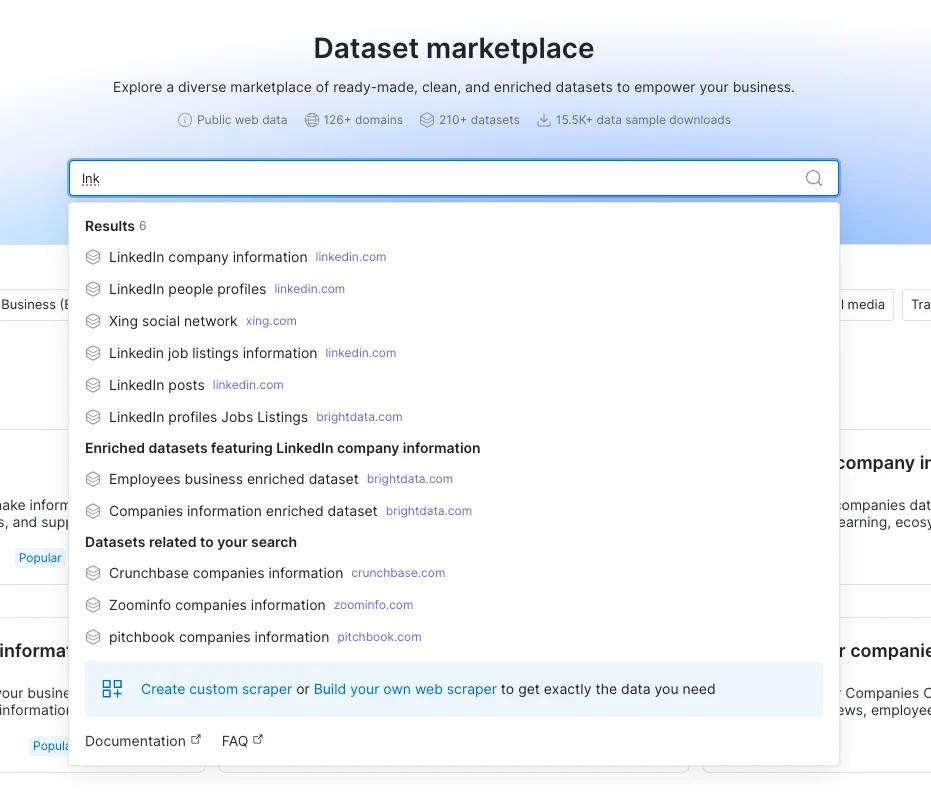
-
Searching for datasets is now more flexible, allowing for slight variations and even typos. This makes it easier to find what you need, even if your search isn’t perfectly accurate.
- Clearer Messages for Filter Limits
-
Reaching the daily filtering limit now triggers a clear message explaining the limit and next steps. You can also submit a request to our data experts for help in refining your dataset filters.
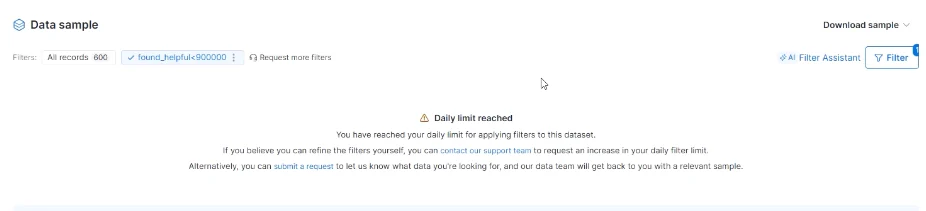
-
Reaching the daily filtering limit now triggers a clear message explaining the limit and next steps. You can also submit a request to our data experts for help in refining your dataset filters.
- Helpful Tooltips for Date Columns
-
Date columns now include tooltips that explain the date format, ensuring you understand that records for the selected dates are inclusive.
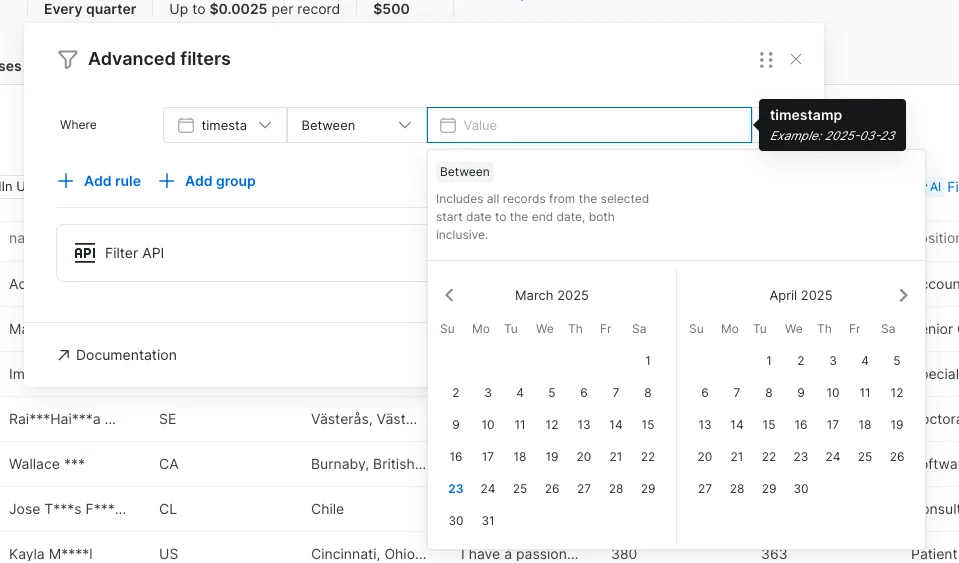
-
Date columns now include tooltips that explain the date format, ensuring you understand that records for the selected dates are inclusive.
🐞 Bug Fixes
- Improved Usability and UI
- We’ve made several design and usability improvements, including fixing typos, to make your experience smoother.
Scrapers:
🆕 New features
- New endpoint allows sync calls to retrieve the scraped data to the requested origin
- We’ve introduced a new endpoint that enables synchronous calls to retrieve scraped data directly from the requested origin, improving efficiency and streamlining the process. This enhancement alongside the upcoming design changes that will be implemented in the next weeks will allow users to access and test their scraped data more quickly and reflect the potential value (link)
- New “Wikipedia articles” scrapers
- Users can now discover (by keyword) and collect article information from Wikipedia.
🚀 Improvements
- Search and navigation
-
We’ve made several improvements to enhance search results and navigation, making it easier for users to find relevant data and explore related products. Search results will now prioritize domain-only results, ensuring more accurate and streamlined discovery. Additionally, Dataset (DS) results will be displayed below Scraper results and vice versa, providing a more structured and intuitive search experience.
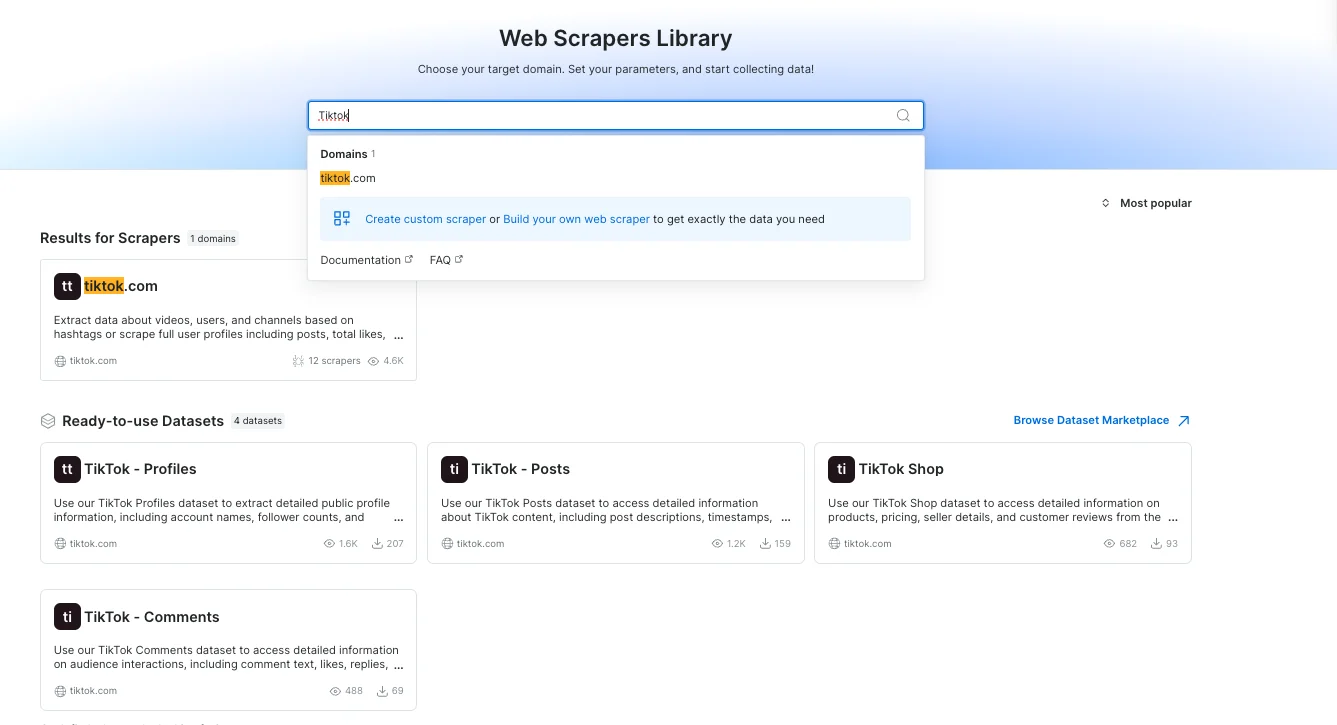
-
We’ve made several improvements to enhance search results and navigation, making it easier for users to find relevant data and explore related products. Search results will now prioritize domain-only results, ensuring more accurate and streamlined discovery. Additionally, Dataset (DS) results will be displayed below Scraper results and vice versa, providing a more structured and intuitive search experience.
- A new banner in SERP to redirect users interested in Chat GPT and perplexity search results
-
This banner redirects users to additional search engine results data, making it easier to access the AI-powered result searches
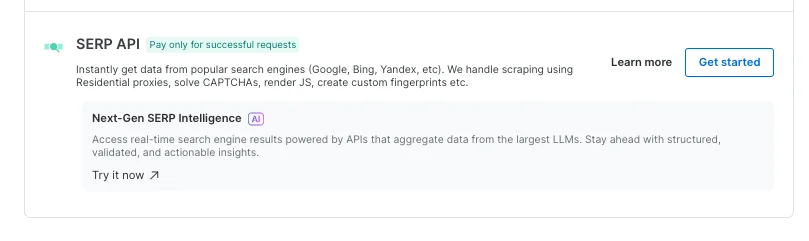
-
This banner redirects users to additional search engine results data, making it easier to access the AI-powered result searches
🐞 Bug Fixes
- Refresh API key Fix
- We’ve resolved an issue affecting the API key refresh option to ensure seamless authentication and session continuity.
- Scraper Request Call Scheduled Notification Fix
- Fixed a bug where scheduled notifications for new custom scraper requests were not triggering correctly, ensuring timely and accurate alerts to the relevant personnel
Release notes for week ending Mar 13, 2025
Web Archive API:
🚀 Improvements
- Hot Storage Duration Web Archive API now offers 72h of hot storage data instead of 96h. For more details see here
Scrapers:
🆕 New features
-
Output Schema Change Monitoring We have released our “output schema change monitoring system” to improve detection accuracy and transparency. Schema change notifications are now consolidated into a single email for customer updates.
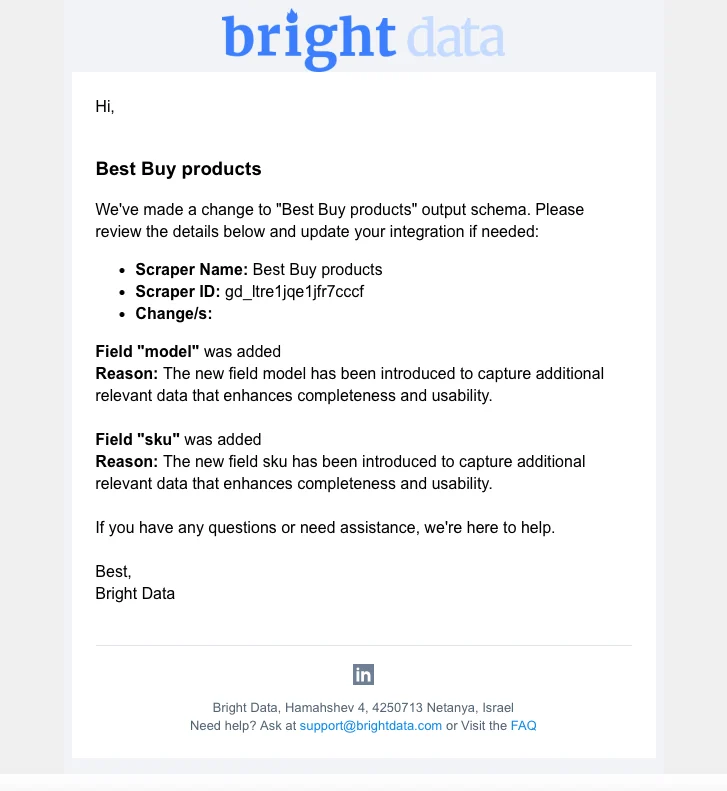
- New discovery method for “Walmart products” Users can now discover and collect product information based on the SKU.
🚀 Improvements
- External Storage Option for Large Files If the compressed file still exceeds 5GB, users will be prompted with an option to send the file to an external storage location for easier access and management.
- Custom scrapers - modify the customs scraper request flow We are now routing calls based on customer type (Community, Named, Key, Strategic), and only the relevant personnel are added to the invite to increase efficiency
- Custom scrapers schema changes agility If there are any changes to the schema defined by the customer during the call, the team can now update the schema before it is sent to the partners.
Proxy products:
🚀 Improvements
- Enable moving datacenter and ISP proxies from legacy pay per GB zones to new datacenter and ISP zones with unlimited plans.
🐞 Bug Fixes
- Fix wrong country assignment for default country in Residential proxy network.
Datasets:
🆕 New features
-
eCommerce Datasets now have Daily & Weekly Subscriptions
You can now get daily or weekly updates for 41 out of 73 eCommerce datasets. This makes it easier to track new products in a category or monitor price changes more frequently. We’re working on adding support for more datasets soon!

-
Improved Filtering Options
- See Matching Records Before Applying Filters – Now you can see how many records match your criteria before applying filters.
-
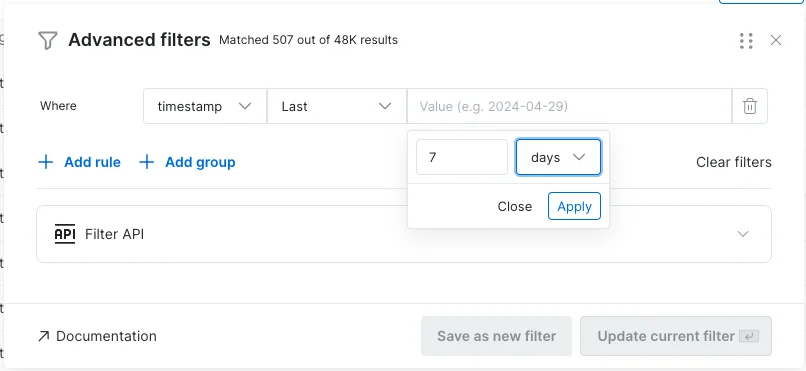
Filter by Date – You can now filter datasets using relative dates for more precise data selection.
-
Estimated Cost Label on Dataset Page view
- We’ve added an estimated cost label below the purchase button so you can see pricing details before buying.
-
A new “Filter Dataset” button next to the cost label lets you quickly refine your dataset selection, helping you get the exact data you need while managing costs.

-
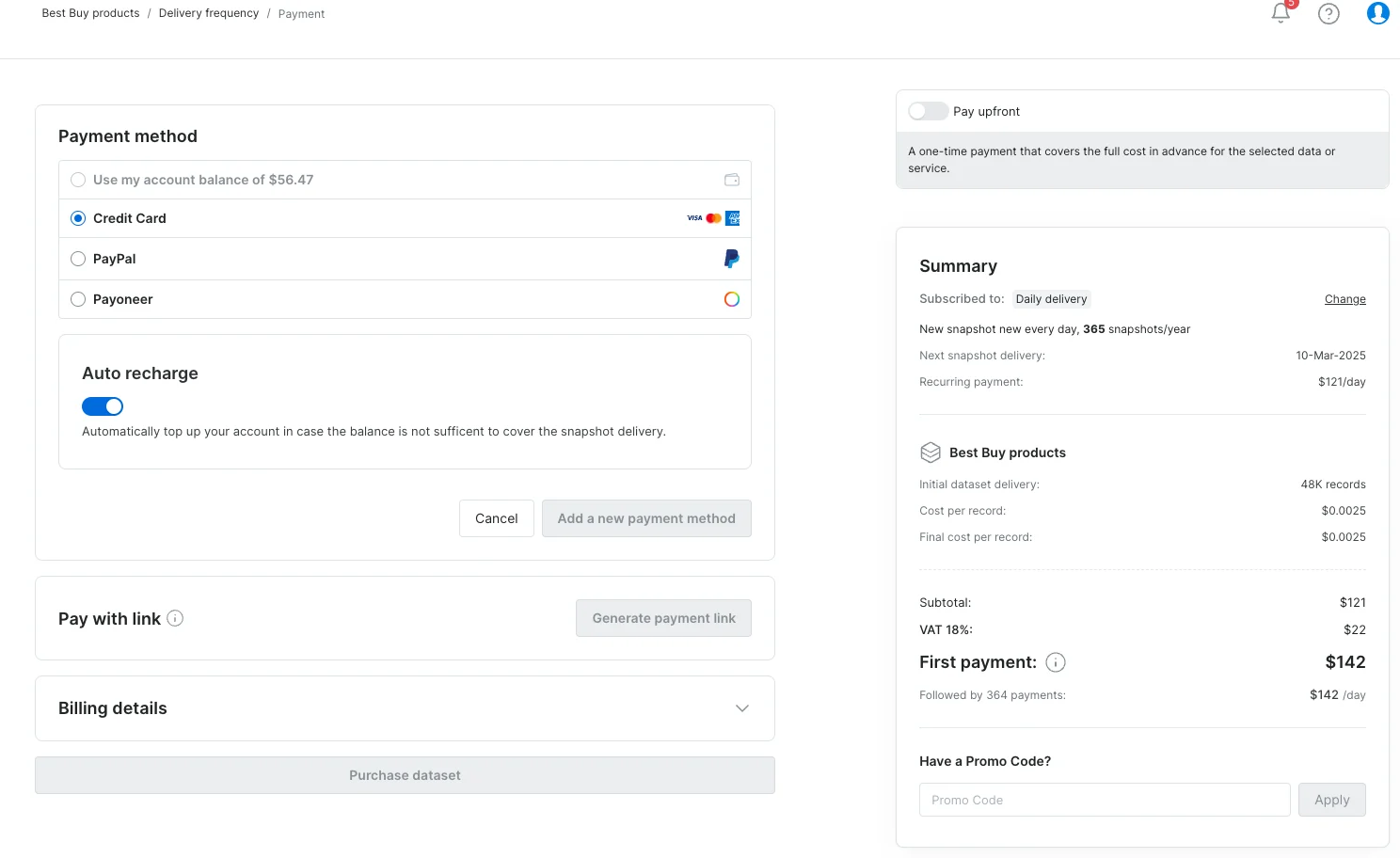
Better Checkout Experience
- Clearer Navigation – Breadcrumbs now guide you through the checkout process.
- Smarter Updates – We’ve improved how we explain delta subscriptions (smart updates) so you can make better decisions.
-
Promo Codes – You can now apply discount codes directly at checkout.
-
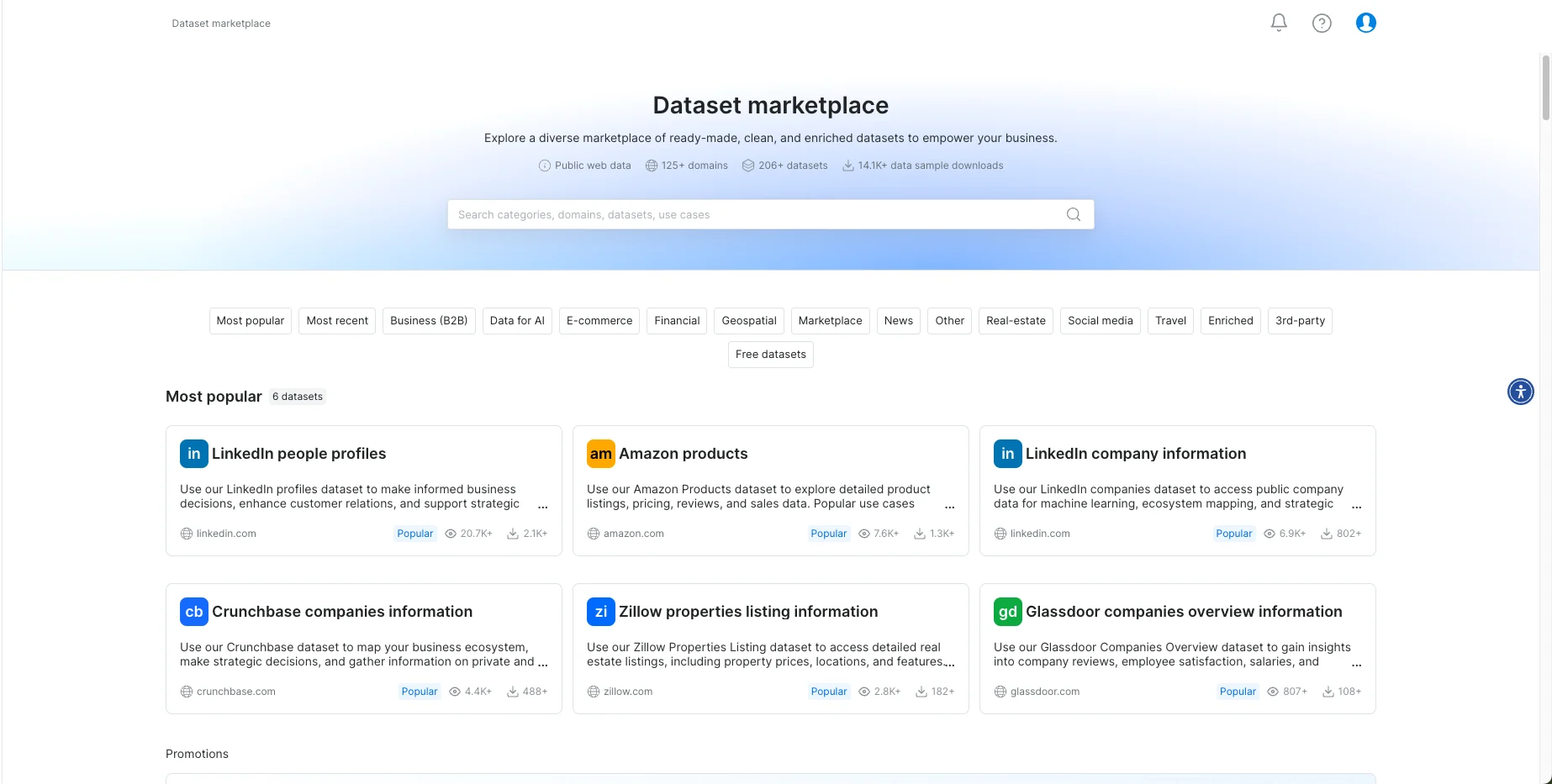
Better Marketplace Experience
- Breadcrumbs in Marketplace – Easily track where you are while browsing datasets.
-
Redesigned Marketplace UI – We’ve refreshed the header, category list, and dataset cards grid to make browsing easier.
🐞 Bug Fixes
- Faster Quote Calculation removed unnecessary calculations in the checkout process, improving performance.
- Subscription Update Fix Updating a dataset subscription no longer redirects you to a different page, it will keep you on the same page.
- Improved Dataset Preview Speed The dataset preview now loads faster for a smoother experience.
Scrapers:
🆕 New features
- Cancel snapshot from the No-Code Scraper – Users can now cancel a running snapshot directly from the No-Code Scraper interface.
-
New logs functionality – New buttons were added to the logs section to provide better interaction options and debugging capabilities to the customers

- New discovery method for “Airbnb Properties” – Allowing users to retrieve Airbnb property information based on filtered URLs.
- New discovery method for “Glassdoor Companies” – Users can now collect company information based on filtered URLs.
🚀 Improvements
UI Enhancements to Scrapers Home Page We’ve improved the usability and navigation of the Scrapers home page enabling faster search, displaying smaller cards for better display and explore more scrapes to users, enhanced Custom Scraper suggestions, and added search within category pages
- Unified the API and No-Code delivery options – We have fixed inconsistencies between the API and No-Code Scraper delivery settings. Now, both methods follow the same logic, making it easier for users to configure and manage their data delivery preferences.
🐞 Bug Fixes
- Fixed broken delivery settings – Resolved an issue that was causing delivery settings to not function correctly. This fix ensures that users can reliably configure and receive their scraped data without disruptions.
- Filter functionality - Filtering my “My scrapers” table according to product is now working
- URL structure - The URL structure were inconsistent across the scrapers pages (e.g, some api_data and some scrapers) now all URLs are consist in structure and contain the word scrapers as part of the URL
- Fixed search results page on Scraper home page – Corrected an issue where search results on the Scraper home page were not displaying correctly. This fix ensures that users can find relevant scrapers more easily.
February, 2025
Proxy products:
🚀 Improvements
-
Added option to breakdown zone statistics by domain in zone overview page:
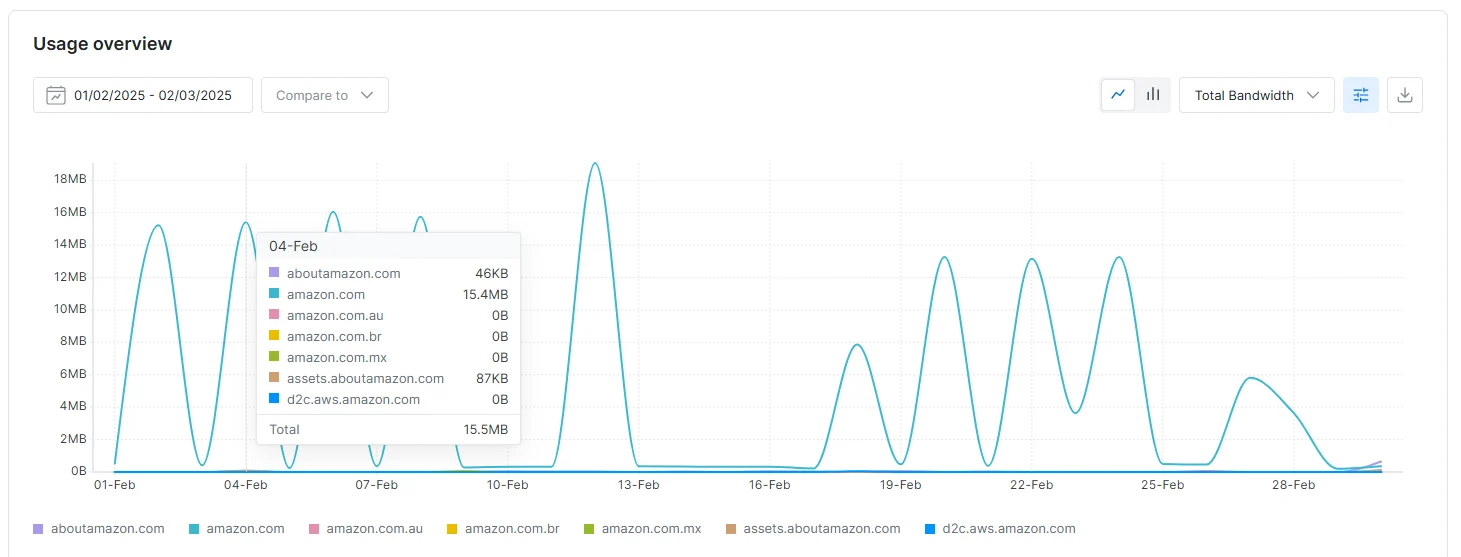
Unlocker API:
🆕 New features
- You can now get HTML automatically converted into Markdown Language. It’s supported both in API and native proxy interfaces. See https://docs.brightdata.com/scraping-automation/web-unlocker/features#scrape-as-markdown
Datasets:
🆕 New features
-
Support for Date Expressions in Dataset Filters:You can now use date expressions in dataset filters (Relative Date), making it easier to refine your data selection based on time-based criteria. This feature is supported in both the Filter API and Dataset Subscriptions, allowing for more flexible and dynamic filtering. Example Use Case: Suppose you want to filter records to include only those from the last 7 days. You can use the “Last” expression to retrieve all records from the past week while excluding older data.
🚀 Improvements
- We have enhanced the way Personally Identifiable Information (PII) is masked to improve data security and compliance.
- Improved Quote Generation Time on Checkout Page - loading time is now faster to get quote data and quote the final price.
- Released a new checkout page. Users can now see added and updated records directly on the checkout page.
🐞 Bug Fixes
- Fixed Preview Table Errors:Resolved an issue that caused slow loading times in the dataset preview table, ensuring faster and smoother data previews.
Scrapers:
🆕 New features
-
Perplexity scraper - Introducing a brand-new Perplexity Scraper, similar to our chatGPT scraper! This scraper allows customers to interact with Perplexity programmatically, retrieving responses as structured data. Now, you can automate queries and extract insights from Perplexity effortlessly. Try it here
- Monitoring system for schema changes – The first release of a monitoring and alerting system for schema changes was implemented to improve data accuracy and stability. It detects changes and sends automatic notifications to ensure seamless data operation. Expect improvements to this system in the coming weeks.
-
New delivery feature for the No-Code Scraper – We’ve added delivery methods, giving no-code users more flexibility in exporting and accessing their scraped data.
🚀 Improvements
-
Enhanced search option to include new result types – The search functionality now displays data points along with their respective scrapers, making it easier to identify relevant scrapers according to their outputs.
- “Deliver to external storage” is now enabled by default – To streamline workflows, external storage delivery is now automatically enabled on the Scrapers, reducing manual setup steps.
- Custom scrapers request - We simplified the request process. Now, it only requires two URLs, and the rest will be handled automatically, to try and streamline the request process
🐞 Bug Fixes
- Resolved issues affecting custom scrapers and implemented an alert system to notify partners when action is required.
- Fixed undefined URL structure – Improved URL handling to ensure consistent and well-defined structures across different pages.
Proxy products:
🆕 New features
- New API will provide the list of proxies pending replacement in advance and prepare for. Try it here: Get proxies pending replacement API.
🚀 Improvements
- Integrate faster with pre-made connect strings for proxy access details (host, port, user and password) accompanied with new set of configuration guides Integration guides.
- We added error codes to our error catalog. Find and resolve issues faster by yourself Proxy errors catalog.
- We have increased our servers deployment in Asia, and added some performance boosts.
SERP API:
🆕 New features
- Google’s Generative AI Overviews - you can now increase the likelihood of this overview appearing in your SERP results:
- Google Trends - new parameters to get more accurate widget specific data:
- `brd_trends = timeseries,geo_map`
- https://docs.brightdata.com/scraping-automation/serp-api/query-parameters/google#trends
Datasets:
🆕 New features
-
Delta Data for Dataset Subscriptions - Customers can now enable delta logic to receive only new or updated records instead of full datasets for every collection cycle. This improves data relevance and allows flexible snapshot comparisons. No more manually identifying changes, as Bright Data does it for you.
🚀 Improvements
- New Pricing Table - A redesigned pricing table provides clearer information, making it easier for customers to understand pricing tiers and make informed decisions.
- Enhanced Dataset Checkout Confirmation Page - The confirmation page has been fixed to ensure a smoother and more reliable checkout experience.
- Improved Error Messaging for Missing Payment Details - Customers attempting to purchase without adding payment and billing details will now receive clearer and more informative error messages.
- Refined Delivery Methods - The order of delivery options has been reorganized, and UI improvements have been made for better usability.
- Keyboard Shortcuts for “Update Dataset” - New keyboard shortcuts have been implemented to streamline dataset updates and UI enhancements for a better user experience.
- Better Data Sample Preview Table - Users can now intuitively open table rows and view object data types in a popover for improved clarity and visibility.
🐞 Bug Fixes
- Fixed Routing Bug - Unnecessary query parameters no longer persist when navigating the dataset page.
- Resolved Promotions Card UI Issue - The promotions cards now display correctly according to the intended UI layout.
Scrapers:
🆕 New features
-
AI Scraper Agents – Our first AI scraper agent allows users to extract data from any website by simply providing its domain. It automatically retrieves all URLs under that domain and extracts content in HTML, Markdown, or plain text. Ideal for AI companies, researchers, and developers needing high-quality text data for training models, analysis, or content generation. Try it here
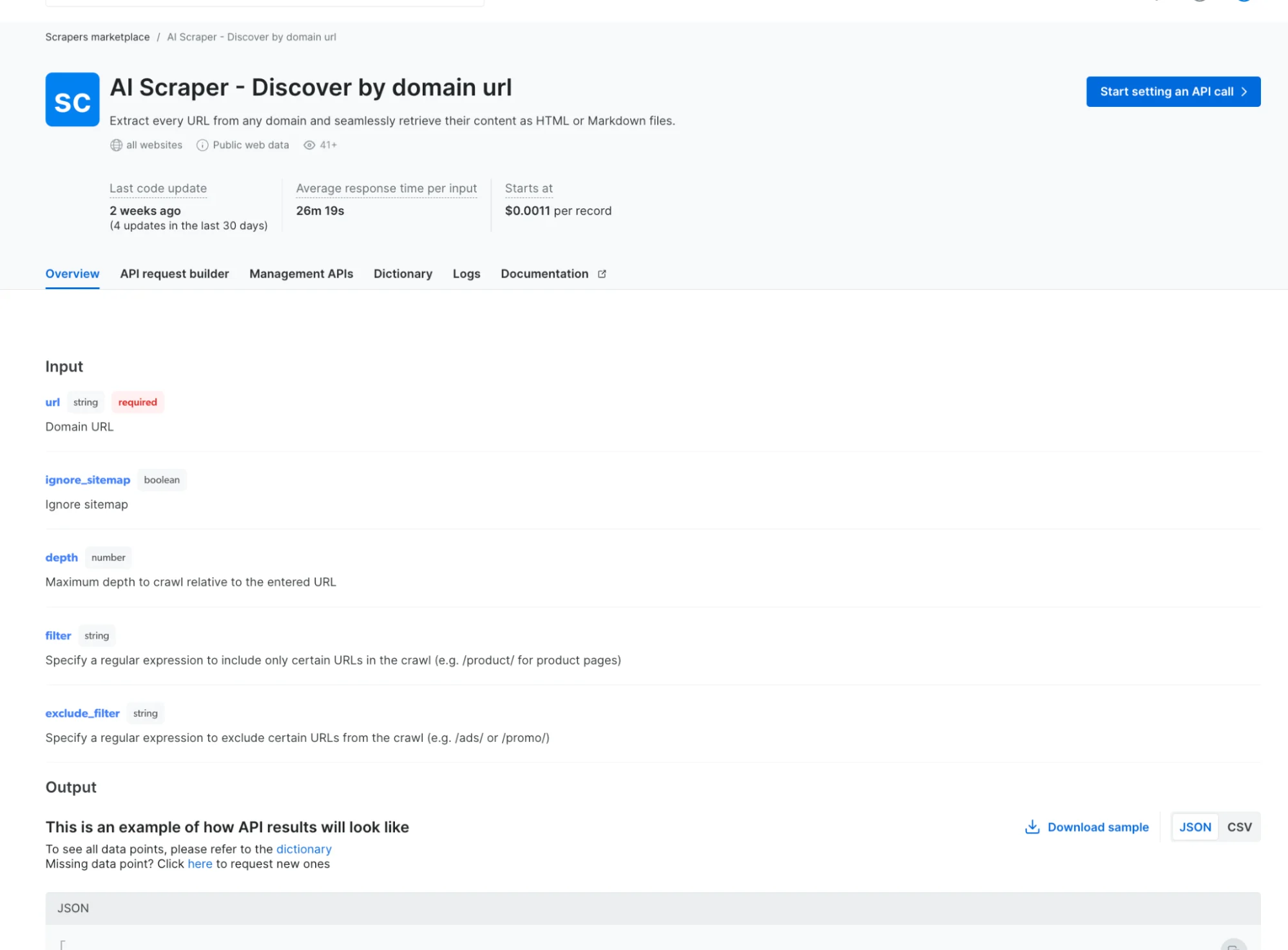
-
ChatGPT scraper - Introducing a brand-new ChatGPT Scraper, similar to our SERP scrapers! This scraper allows customers to interact with ChatGPT programmatically, retrieving responses as structured data. Now, you can automate queries and extract insights from ChatGPT effortlessly. Try it here
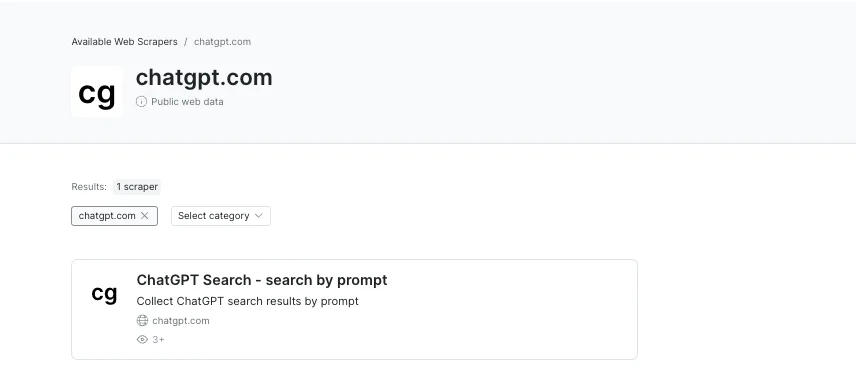
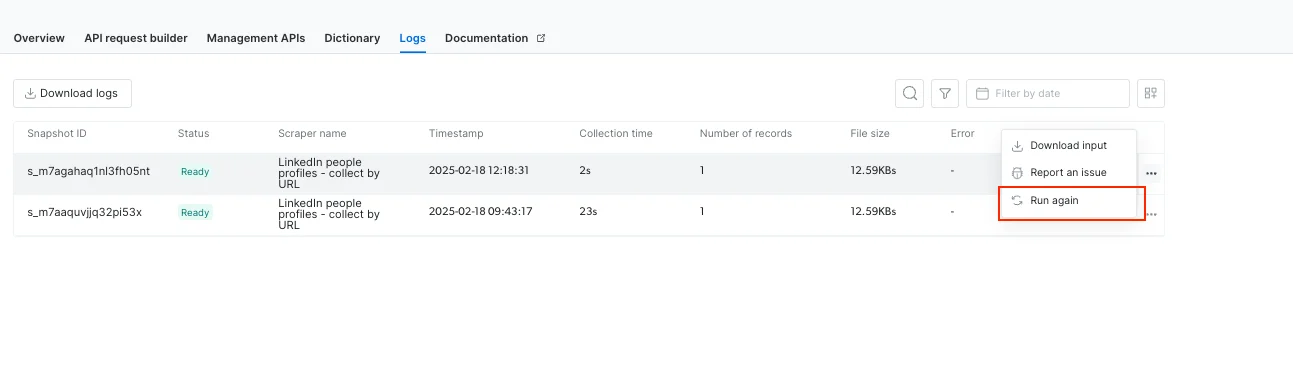
-
“Run Again” Button in Logs Page - We’ve added a “Run Again” button to the Logs page, allowing users to quickly re-run the same request with a single click. making it easier to retry failed or past jobs without manually re-entering parameters.
🚀 Improvements
- My scrapers table- Scrapers that are currently running or the most recent scraper that was in use will now appear at the top of the “My Scraper” table. This makes it easier to track active jobs without having to scroll through completed ones.
- WSA API- To improve navigation and organization, we’ve moved the “Delivery Options” section to the “Management API” tab. This change makes it more intuitive for users managing API-based data deliveries.
🐞 Bug Fixes
- If a collection job fails in the No-Code Scraper, users can now download error details to better understand what went wrong. Previously, the download button was disabled, making debugging difficult. This improvement ensures better transparency and troubleshooting.
- We’ve resolved an issue where the “Report an Issue” feature did not correctly associate snapshots with tickets. Now, when customers report a problem, the correct snapshot is automatically linked, making it easier to troubleshoot and resolve issues efficiently.
Proxy products:
🆕 New features
- HTTP3 beta is live - The proxy network was upgraded to handle HTTP3/QUIC requests. Contact Bright Data sales - sales@brightdata.com if you want to try it out!
🚀 Improvements
- It is now easier to copy your proxy credentials on the ‘overview’ tab, in different formats.
🐞 Bug Fixes
- Fix broken code examples on account management API doc playground
- Added missing documentation for endpoint and some old doc links not redirecting properly.
Datasets:
🆕 New features
-
“AI Filter Assistant” allows users to filter datasets using Natural Language - just describe desired filters in English and get the relevant records.
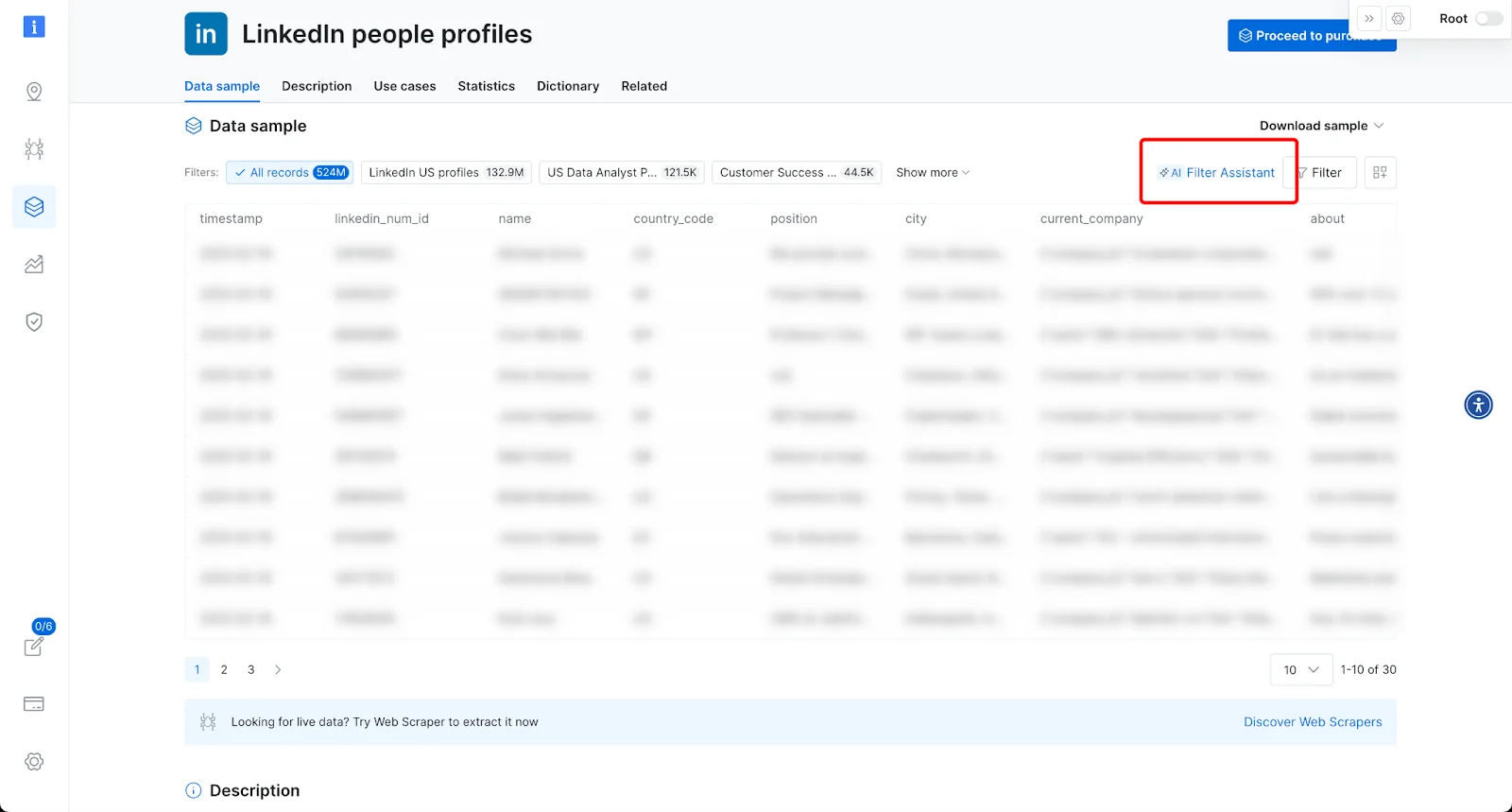
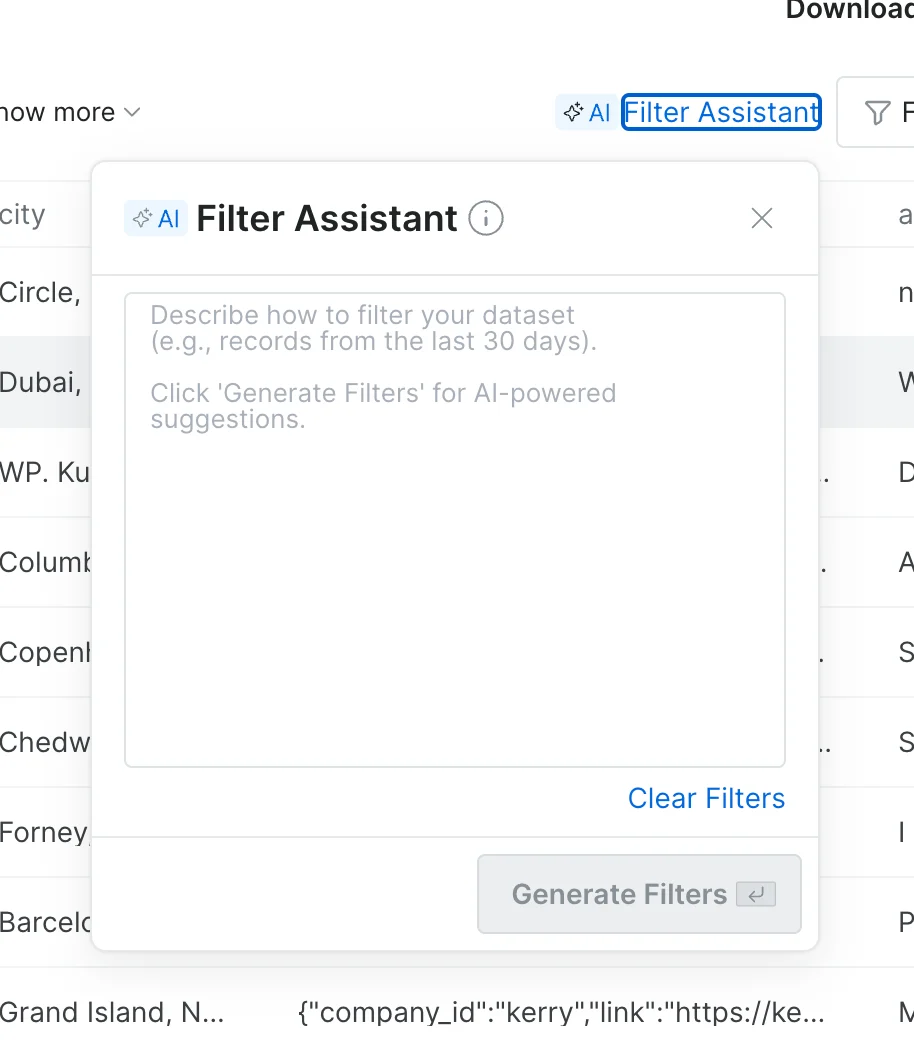
-
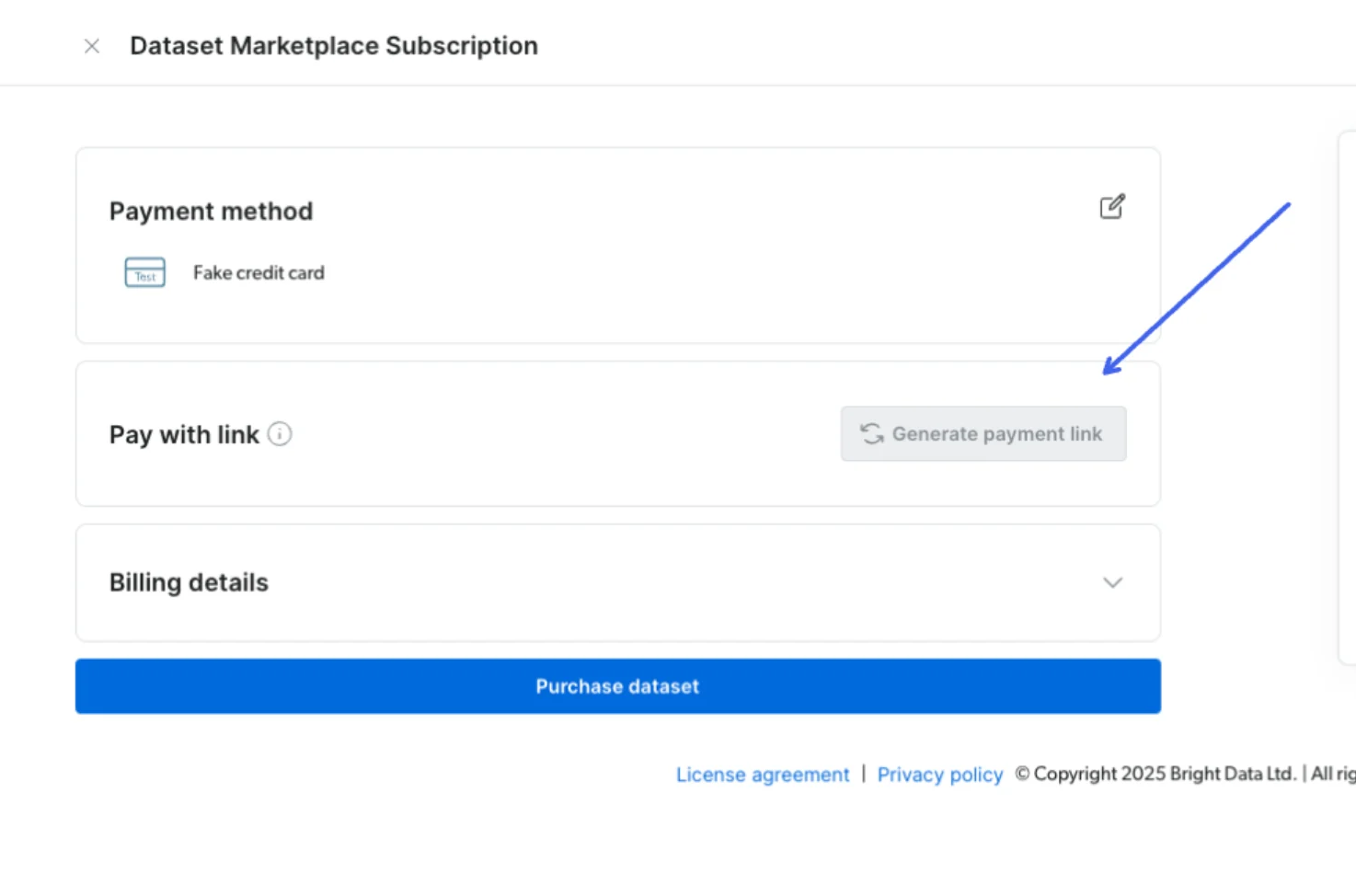
Payment Link Sharing – Dashboard users can now generate and share payment links, making the purchasing process easier for others (e.g. their CFO) without logging in to the control panel.
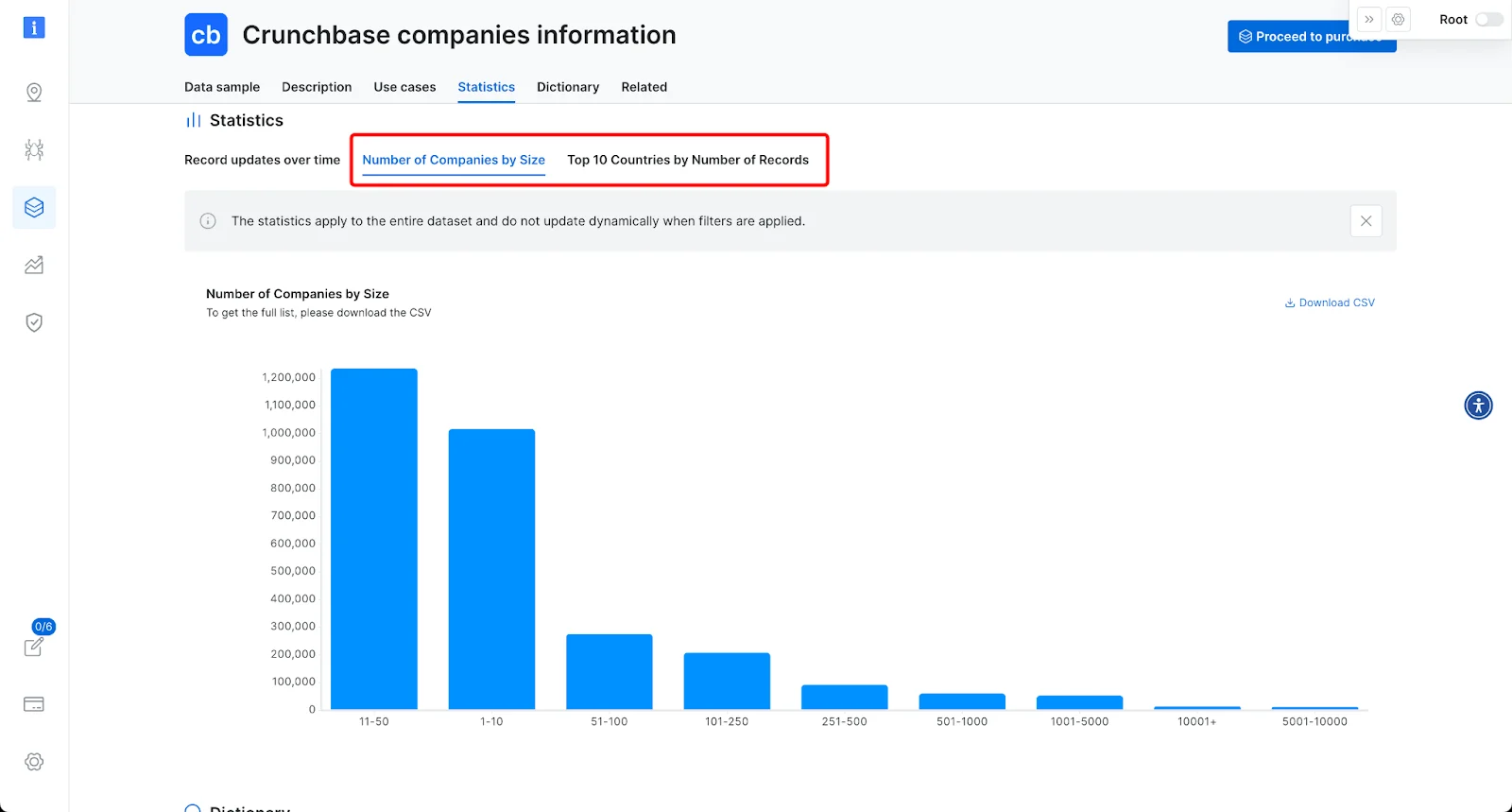
-
Additional Dataset Statistics – Each Dataset now includes additional statistics regarding its content, for example: geographical distribution of records. This information is updated every month.
🚀 Improvements
- Enhanced Filtering Experience – You can now move the filter window while reviewing and refining your filters and datasets. No more hiding of the table!
- Better data sample preview – We’ve limited the cell size for better readability. You can now click on fields to expand and view the full data point in the sample dataset.
🐞 Bug Fixes
- Fixed incorrect parsing of CSV files uploaded as inputs to the filter component.
- Made sure the record count always gets updated, to show the effect of the filter.
Scrapers:
🆕 New features
- Custom scrapers - Allows users to request a custom scraper if the domain is unavailable in our marketplace. Just supply 2 URLs to get the process started - see the video!
🚀 Improvements
- An automatic email notification that is being sent after a customer triggers a scraper for the first time, for better onboarding experience.
- Added code examples in multiple languages to allow users to copy the API code in their preferred language on all of our API requests
- Reduced the number of examples from 10 to 5 in the “Overview” tab to provide a “clear” view to the users
- Sophie: Users can now ask questions about specific use cases and receive relevant suggestions along with a direct link to the dataset.
🐞 Bug Fixes
- Fixed broken links across the Scraper pages.