- Scraping data from websites without getting blocked
- Emulating real-user web behavior
How can I get started?
How can I get started?
To disable CAPTCHA solving just open the relevant zone, go to the ‘configuration’ tab and open the advanced settings where you will find the ‘Automatic Captcha Solving’ controller. To disable CAPTCHA solving just switch off the toggle.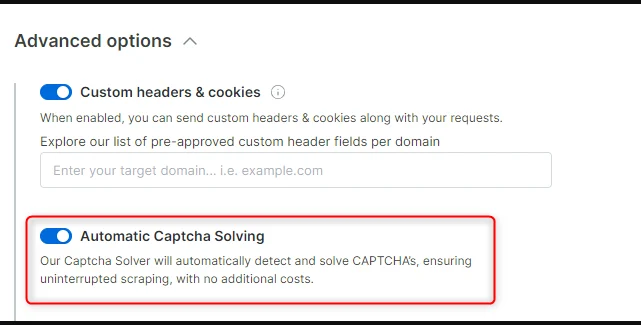
If you would like to manually configure our default CAPTCHA solver through CDP commands on your own, see custom CDP functions